After Part 07 wired up the four checks, latency became the next design problem
Part 07 got faithfulness checking, citation checking, Langfuse tracing, and cost tracking all working in production. The moment we turned them on, though, running full faithfulness + full trace + full citation on every query pushed p95 latency from 1.5s to 6s, tripled cost, and shot the bounce rate up.
The problem wasn’t that the capabilities were wired wrong. It was that they were wired uniformly. In practice, RAG queries naturally fall into a few clusters:
- “How do I reset my VPN” / “What’s our API rate limit” — FAQ style. Short answer, fixed source. Getting it wrong is rarely fatal.
- “What does clause 3 of this MOU say” — Contract style. Getting it wrong is expensive. Faithfulness + citation both required.
- “Help me debug why this query is slow” — Debug style. Needs stage-level trace and deep evaluation.
- “What’s this Q3 report actually about” — Summarisation style. No right answer, just usefulness.
- “Compare the Q3 contract against the Q2 one” — Multi-step style. One retrieval pass can’t carry it.
Running the same checks on all five clusters is the wrong default. Running faithfulness on a VPN-reset question wastes latency and cost. Running pure vector search on a contract clause removes the safety net where it matters.
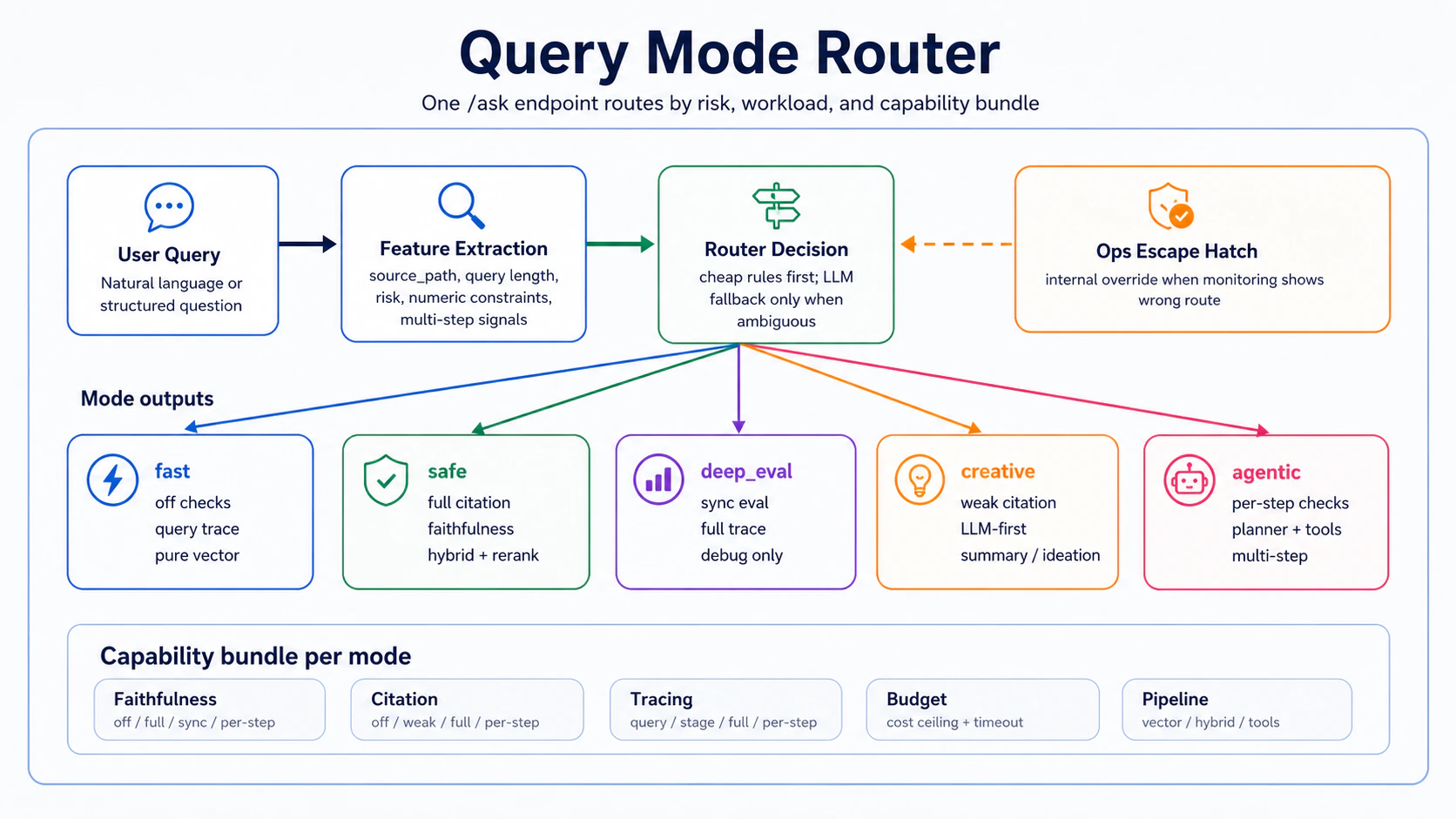
So you split. The way you split is what Part 08 is about: a single /ask endpoint that decides, per query, which of the four capabilities to run and how. Routing is a well-trodden pattern — LlamaIndex’s RouterQueryEngine and LangChain’s RouterChain both ship official implementations. Not new.
The twist here is what we’re routing. We’re not routing to different prompt templates — we’re routing to different capability bundles. The router function looks at the query and answers four questions:
- Does this one need faithfulness checking?
- How deep does citation go?
- Query-level or stage-level trace?
- What’s the cost ceiling for this call?
The combination of those four answers is which mode this query should take.
Tested API-shape note: the snippets in this article show the implementation shape used by this project, not a permanent SDK contract. Pin your Python packages, keep a minimal smoke test for each snippet, and re-check LlamaIndex / Qdrant / FastAPI / evaluation-framework docs when upgrading.
Five modes, four capabilities, mapped
The five modes from the end of Part 07 are the starting point for this post, not a decorative recap — turn each capability on, off, or weakened, and you land on five meaningful production modes:
| mode | faithfulness | citation | tracing | cost / query | p95 latency | pipeline |
|---|---|---|---|---|---|---|
| fast | off | off | query-level | ~USD 0.001 | < 1s | pure vector search |
| safe | full + async RAGAS | full | query + stage | ~USD 0.01 | < 3s | hybrid + rerank + parent expansion |
| deep_eval | sync RAGAS + LLM judge | full | full trace | ~USD 0.10 | 5–15s | full pipeline + sync eval |
| creative | off | weak (presence only) | query-level | ~USD 0.02 | < 2s | llm_first synthesis + light retrieval |
| agentic | per-step | per-step | per-step trace | ~USD 0.05/step | < 4s/step | multi-step planner |
A caveat on this table: these numbers are from my own system’s measurements and a rough read of common industry benchmarks (thedataguy.pro’s RAG cost writeup / Tetrate’s RAG architecture patterns). They’re not vendor SLAs and not platform guarantees. The same query run on Cohere / OpenAI / MiniMax / a self-hosted LLM can come back 2–5x different in latency and cost. The gap from USD 0.001 to USD 0.10 in the table is the gap from running one query in two different modes — that’s an architecture decision, not a model decision, and switching to a cheaper model won’t close it.
This is also how Part 02 and Part 03’s 14 stations should be read: each mode activates a subset of the capability map. fast intentionally skips most verification and context-expansion stations; safe turns on the stations needed for grounded document QA; deep_eval adds the expensive evaluation stations for debugging and regression. The map defines available capabilities; the router decides the runtime path.
The on/off settings for each mode’s faithfulness and citation, and the strength of the retrieval pipeline, aren’t picked by gut feel — they map to the failure cost of the query:
- fast maps to “wrong answer isn’t fatal” queries — a VPN-reset answer gone wrong means the user asks again. So we drop every check and buy back 1s of latency.
- safe maps to “wrong answer costs money” queries — a contract clause misread can cost the company real damages. All checks on, async RAGAS sampling, trace down to stage-level.
- deep_eval maps to “something’s broken and we need to know which stage” — not a user feature, it’s a debugging tool. Sync RAGAS + LLM judge, every stage visible.
- creative maps to “no right answer, just usefulness” — summarisation, brainstorming, marketing suggestions. Faithfulness has no meaning here (there’s no “correct” source) but a thin layer of citation stays so the user can trace back.
- agentic maps to “one retrieval pass can’t carry it” — cross-document comparison, risk analysis. Has to be split into steps, each with its own trace and its own faithfulness check.
The switch is keyed to the cost of being wrong.
Where you put the routing layer is the first design decision
The first question for getting these five modes into production isn’t “how do I design the routing logic” — it’s “where does the routing layer live.” Three options:
- URL-level split —
/ask/fast//ask/safe//ask/agentic. The frontend picks the mode. A bad client choice breaks the query. - Request payload carries a
modefield —{"query": "...", "mode": "safe"}. Flexible API. A client that sends the wrong mode sends a contract through fast. - Server-side auto-detection — the API doesn’t take a mode parameter; it picks based on query features and business metadata. Production-friendly, but the router has to be written correctly.
Options 1 and 2 push the decision to the client. Client engineers don’t always know the risk profile of their own queries, and a wrong pick at request time breaks the contract. Option 3 (server-side) sounds ideal, but a router bug is just as bad as a client mistake — a contract landing in fast, a safe query landing in creative, both break the same way. The difference is that a server-side bug is harder to find than a client mistake — a client mistake shows up in the request log, a server-side bug hides inside the router logic. Part 08 goes with option 3, but with one safety net: the request can still carry a mode field to force-override the auto-detection.
This force-override (commonly called an escape hatch) is not for the end user. It’s for ops to grab when production monitoring shows “this query should have gone to safe but went to fast” and they need to flip it immediately — they can’t wait for an engineer to change routing code and deploy. Full automation still needs an operational override path, and the escape hatch is how this system keeps that control explicit.
This is the first failure scenario for routing: the auto-router gets it wrong and sends a contract query to fast. The guardrail is the escape hatch plus a post-hoc monitoring alert. Without the escape hatch, you are waiting for the next deploy to fix a production routing error.
Routing has two layers: mode router and pattern router
The original Part 08 was mostly about the mode router: should this query run as fast, safe, deep_eval, creative, or agentic? That layer chooses the capability bundle: how much faithfulness, how much citation, how much trace, how much budget.
But once a RAG system gets closer to production, a second layer appears: the pattern router. It does not ask “how many checks should we turn on?” It asks “what kind of thing should this query retrieve in the first place?“
| routing layer | question it answers | typical outputs |
|---|---|---|
| Mode router | Which capability bundle should this query use? | fast / safe / deep_eval / creative / agentic |
| Pattern router | What retrieval pattern should this query use? | document RAG / SQL or API tool / long-context pack / agentic workflow |
Do not collapse these two into one blob. That collapse creates a very common failure mode: the user asks “which 10 tenants had the highest query cost last month,” and the router sends it to vector search as if it were a document question. The vector database may retrieve plausible documents, and the LLM may write a fluent answer, but the result is still wrong because the source of truth should have been Postgres or a billing table.
So the core of Part 08 becomes this:
The
/askendpoint should not only decide “does this query need checks?” It should also decide “which retrieval pattern should this query use?”
This is also why agentic mode matters. Once a query crosses retrieval patterns — first query SQL to identify high-risk tenants, then search policy documents, then assemble a risk explanation — one retrieval pass cannot carry the task. The fix is not raising top_k; the fix is a bounded multi-step workflow.
Six query features decide the path
The easiest trap to fall into in auto-routing is “give the router an LLM, have it look at the query and pick a mode.” That path creates three production risks:
- The router LLM itself has cost and latency — when you tally production cost, that call counts too. It’s not free.
- The cost of a router LLM getting it wrong is high — misclassifying a contract as an FAQ makes the whole pipeline downstream fail in a chain.
- Router LLMs can drift over time — model upgrades and small prompt changes may shift router behaviour, and router issues are harder to debug than ordinary query failures.
The right order is cheap features first to pre-filter, LLM fallback only when genuinely ambiguous. Six query features, ordered by the cost of obtaining them:
# router/features.py
from dataclasses import dataclass
@dataclass
class QueryFeatures:
# Free features (no LLM needed)
source_path: str # "contract" / "faq" / "runbook" / "open"
has_explicit_citation: bool # did the request ask for [1][2] citations
query_length: int # character count
is_multi_step: bool # detect "and then" / "next" / "step 1 step 2"
# Medium-cost features (regex or a small classifier)
has_numeric_constraints: bool # "60 days" / "6 months" / "USD 10,000"
domain_risk: str # "high" / "medium" / "low" - derived from source_path
# High-cost features (LLM call, only in genuinely ambiguous cases)
intent_classifier: str # "factual" / "summarization" / "open-ended"The decision tree:
Step 1: is_multi_step = True → agentic
(is_multi_step uses regex to catch "and then / next / step 1 step 2" — **this is a known production failure mode** — a user writing "next" might mean a narrative, not a multi-step task. The threshold and keyword set have to be tuned on real query samples, you can't pick them out of the air. Misclassification either direction hurts: fast/safe wrongly routed to agentic gets 5–10x slower, agentic wrongly routed to fast/safe can't decompose the multi-step logic.)
Step 2: domain_risk = "high" → safe
Step 3: has_numeric_constraints AND source_path ∈ contract/legal → safe
Step 4: intent_classifier = "summarization" AND source_path = "open" → creative
Step 5: source_path ∈ faq/runbook AND query_length < 50 → fast
Step 6: everything else (including ambiguous) → safeA word on why Step 6 defaults to the strictest mode — the cost of a wrong routing direction is asymmetric: misrouting fast to safe wastes money, while misrouting safe to fast can create business or safety risk. So default to strict, and only downgrade with a clear reason. This asymmetry runs against the usual instinct for routing system design (most routing systems default to the middle), and the most common rookie mistake in RAG routing is setting the default to fast, planning to fall back to safe when needed — that’s exactly where the failures land.
Why Step 4 needs an LLM call for intent classification: Steps 1–5 can’t all classify every query. “What is this Q3 report about” — summarisation or factual lookup? Cheap features can’t tell, the router has to make one LLM call. Skipping that call means hard-guessing with regex — and the failure cost of a wrong guess is the same as the Step 6 default being wrong. The cost model has to include that call.
The second failure scenario for routing: someone flips the Step 6 default to fast to “save cost.” It might look fine for the first three months, but as contract query volume grows, the router doesn’t get the message to flip it back, and faithfulness failure rate creeps up until something breaks. The guardrail is that “default strict” is a non-negotiable — and the Step 6 behaviour is pinned in CI, not left to memory.
One important branch: Structured / SQL RAG
Not every question should go through vector retrieval.
Some answers live in a database, an API, a metrics table, or a billing table, not in document chunks. Examples:
- “How much query cost did each tenant generate last month?”
- “Which 10 users have the highest citation failure rate?”
- “What is the failure distribution for ingestion jobs this week?”
- “How many Q3 contracts have
status = expired?”
If you send these to a vector DB, the retriever may find documents about cost, failures, or jobs, but those documents are not the source of truth. The right route is Structured / SQL RAG:
User query
→ structured intent
→ readonly SQL / API allowlist
→ tenant / user permission filter
→ timeout + row limit
→ structured result table
→ answer with query provenanceThe key point: SQL RAG does not mean letting the LLM freely write SQL. In production, the safer pattern is to have the LLM produce a structured intent, then let the backend map that intent to reviewed SQL templates or approved API functions.
For example:
class PatternRoute(Enum):
DOC_RAG = "doc_rag"
SQL_TOOL = "sql_tool"
LONG_CONTEXT = "long_context"
AGENTIC = "agentic"
@dataclass
class RouteDecision:
mode: Mode
pattern: PatternRoute
reason: strIf the query contains KPI, count, top N, group by, time range, or status distribution signals, and the source of truth is the app DB, the pattern router should choose SQL_TOOL, while the mode might still be safe. In other words: SQL is the data acquisition pattern; safe is the checking intensity. Keep those two layers separate.
That separation is one of the differences between a demo and a production system. Demos often have one road: query → vector → LLM. Production should be: query → route → choose tool / retriever / checking depth.
Agentic RAG is not permission for the agent to roam free
The agentic mode is easy to misunderstand as “let the LLM decide what to do next.” That is charming in a demo and dangerous in production.
In this project, the useful version of agentic RAG is not an unbounded agent. It is a bounded multi-step workflow:
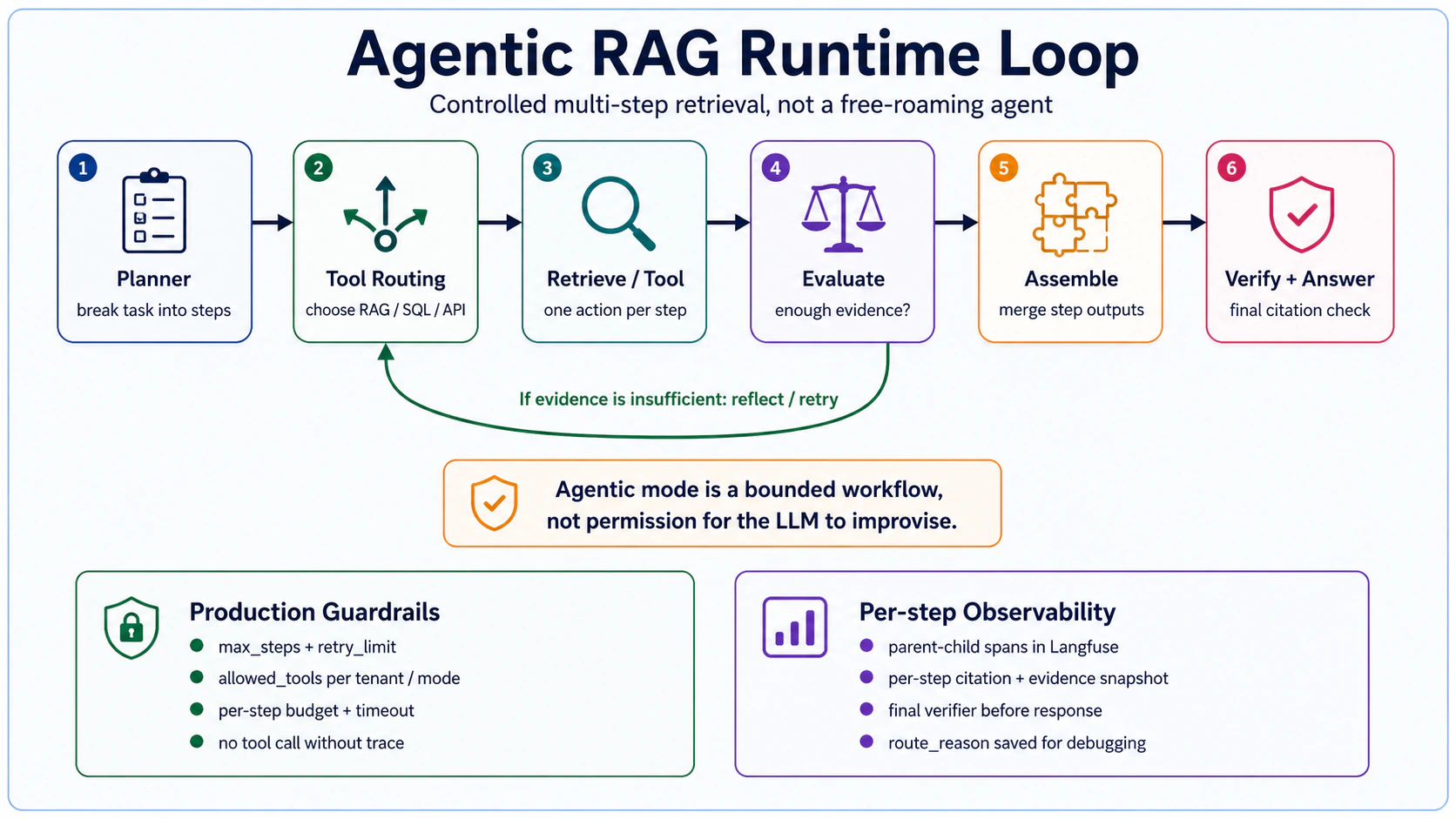
Planner
→ Tool routing
→ Retrieve / tool call
→ Evaluate evidence
→ Reflect / retry when needed
→ Assemble context
→ Verify + answerEvery step needs boundaries. An unbounded agentic workflow creates three failure modes:
- Step explosion — the planner keeps decomposing until one query becomes a tiny workflow storm.
- Tool explosion — the LLM starts calling tools it should never call for this task.
- Error compounding — step 1 is wrong, step 2 quotes step 1’s wrong intermediate conclusion, and the final answer looks polished while the whole chain is tilted.
So production agentic mode needs at least these guardrails:
| guardrail | purpose |
|---|---|
max_steps | cap the number of steps |
retry_limit | prevent infinite reflect / retry loops |
allowed_tools | restrict tools by tenant and mode |
| per-step budget | cap token and latency per step |
| tool timeout | keep a stuck tool from blocking the whole request |
| per-step trace | record each step as a Langfuse parent-child span |
| per-step evidence | store citation / source snapshots per step |
| final verifier | still run citation / faithfulness before the final answer |
The difference between normal RAG and Agentic RAG is not that agentic is “smarter.” It is that the error surface is bigger, so it needs more tracing, budgeting, and verification.
| Normal RAG | Agentic RAG |
|---|---|
| one query, one retrieval pass | one task split into multiple steps |
| fixed retriever | each step can choose a different tool / retriever |
| context is assembled directly | each step checks whether evidence is enough |
| final answer is generated | intermediate results affect later steps |
| debug one trace | debug parent-child spans |
Without these guardrails, agentic mode is not a production upgrade. It is a larger error surface with a better name.
For each mode: when to use it, when not to, and how it fails
Every mode needs all three, otherwise production breaks.
fast: pure vector, zero checks
When to use it: FAQ, known runbooks, internal knowledge bases with stable structure. Short query, short answer, concentrated sources, wrong answer isn’t fatal.
When not to use it: any query where a wrong answer hurts. Contract amounts, patient dosages, customer PII — running these on fast means faithfulness failure rate near 100%. The Q3 early-termination contract case from Part 07 would produce an answer under fast mode that looks exactly like what Part 06 produced before the retrieval fixes — skipping faithfulness drops the safety net.
Failure modes: (1) vector recall drops when synonyms aren’t covered (“early termination” isn’t in the chunk title, fast misses it); (2) no rerank filter, multi-section documents pull in too much noise; (3) no trace, errors don’t get debugged.
The third failure scenario for routing: once the system is live, an operator feels fast isn’t accurate enough and bolts a rerank onto it — fast’s cost and latency both go up, and the boundary between the five modes collapses. The fix for “fast isn’t accurate enough” isn’t to change fast, it’s to reroute that query to safe.
safe: contracts, legal, medical
When to use it: the Q3 contract case from Part 06, legal clause lookup, MOU clause query. This is the main workload Part 07’s faithfulness + citation checks were designed for.
When not to use it: low-risk FAQ. Running safe on FAQ is usually overkill — 5–10x the cost, no meaningful faithfulness gain (FAQ answers are short to begin with and citation doesn’t need to be that deep). Also, real-time back-and-forth chat — 3s latency versus fast’s 1s slows down the user’s conversational rhythm noticeably.
Failure modes: (1) false-positive faithfulness — the LLM judge says a claim has no source backing when it does, just phrased differently; (2) async RAGAS sampling rate set too low, long-tail failure cases never get scanned; (3) cost blowout — parent expansion without budgeting, context stuffed with too many tokens, safe mode is the most likely of the five to blow cost.
deep_eval: debugging and regression
When to use it: (1) before/after changing prompts / chunking / rerank, for offline A/B; (2) when production is misbehaving, open 5% sampling and pull stage-level trace to find the broken stage; (3) CI runs offline eval on 50–100 questions.
When not to use it: not on the regular production user path. Deep_eval with sync RAGAS + LLM judge takes 5–15s per query, 100x the cost of fast, 15x the latency.
The fourth failure scenario for routing: ops opens deep_eval to 100% of user traffic to “see more trace,” p95 jumps from 1.5s to 12s — bounce rate spikes, API quota burns through. The Langfuse dashboard will misdirect at the same time: stage-level trace shows rerank as the bottleneck, but it isn’t — it’s the sync RAGAS waiting on the LLM judge. The async 5% sampling pattern from Part 07 was designed exactly to avoid this, but anyone who bypasses async and calls sync directly defeats it. The guardrail is to wrap sync deep_eval behind
if user is internal_ops: ...and never expose it to regular users.
Failure modes: (1) LLM judge results aren’t reproducible — running the same question twice can swing faithfulness scores by 0.1, which makes a 0.05 CI threshold flake; (2) the offline dataset goes stale, chunking changes but the dataset still scores against the old chunks, and accurate-looking scores become misleading; (3) sync deep_eval goes to the wrong path (the scenario above: ops accidentally opens it to 100% of user traffic).
creative: open-ended Q&A, summarisation
When to use it: “What is this Q3 report about”, “Give me three takeaways”, “Suggest a new marketing direction.” No right answer, just usefulness.
When not to use it: factual lookup, anything needing citation. Running creative on the Q3 early-termination penalty would be the wrong mode — faithfulness off means the LLM is free to hallucinate, contract clauses get freely interpreted.
Failure modes: (1) once you switch to llm_first synthesis, the LLM tends to “over-expand” — the user asks for three points, gets back eight, token cost and latency both overshoot; (2) weak citation set too loose becomes no citation, the traceability the user wanted is gone; (3) the boundary with safe gets fuzzy — “how do we read this report’s pricing strategy” — summarisation or factual? The rule is: source_path = "open" is the only path that allows creative, anything else goes to safe.
agentic: multi-step tasks, cross-document reasoning
When to use it: “Compare the Q3 contract against the Q2 one”, “Pull a risk matrix out of three reports.” A single retrieval pass can’t carry it, you have to split into steps.
When not to use it: pure “find me a passage” or “summarise this passage”. Agentic on FAQ is 5–10x slower and 5–10x more expensive than fast — the planner and per-step faithfulness overhead are fixed costs, they don’t shrink just because the query is simple.
Failure modes: (1) planner decomposes the steps wrong — the retrieval query in step 2 doesn’t connect to the result from step 1, and downstream faithfulness fails in a chain; (2) per-step faithfulness is poorly designed, step 1 is wrong, step 2 quotes step 1’s wrong result, error compounds and amplifies; (3) per-step trace is not modelled as Langfuse parent-child spans, debugging agentic has a different structure from debugging normal queries, and no per-step trace makes agentic debugging impractical.
How the number five got pinned
Fair question: why five and not three, not eight?
Starting coarse: in the early days we tried splitting into just “fast” and “slow” — fast ran FAQ but also contracts, slow ran every high-risk query. That sacrificed both ends at once: fast-on-contracts broke (the “when not to use” for fast covers this), slow-on-creative (summarisation) got dragged 3 seconds slower by faithfulness and users bounced. Below five modes the granularity is too coarse — some mode always pays a cost it shouldn’t for some query cluster.
Starting fine: we also tried splitting safe into “safe-contract”, “safe-legal”, “safe-medical” — three modes whose capability bundles were almost identical, and debugging tripled in difficulty, so we merged them back into a single safe. Above five modes the granularity is too fine — each new mode adds a maintenance burden to the codebase with no meaningful capability difference.
Two hard questions you can apply directly to “should this be split / should this be merged”: (1) if two modes’ capability bundles are 80% the same, merge (avoid stacking for the sake of stacking); (2) if the same mode running different queries has faithfulness and cost differences over 3x, split (one mode is covering too much and ends up torn between “backing the high-risk case” and “backing the low-cost case”). That’s also why five isn’t a magic number — it’s the middle ground that survived both finer and coarser attempts, not a lucky observation.
The fifth failure scenario for routing: production traffic grows, someone notices a mode is over-represented in volume (say fast at 60%) and decides to “simplify by dropping the other modes and keeping only fast.” That buries every high-risk query alongside it. The guardrail is that the number of modes is tied to the observed kinds of query risk, not to traffic share.
Router implementation, the parts that matter
The most common mistake, already covered above, is “shove an LLM into the routing layer and have it pick the mode” — that path is wrong in all three ways (cost, misjudgement, drift). The right order is cheap features → rule-based pre-filter → LLM fallback only when ambiguous — LLM is the fallback, not the default path. Same design instinct as “n8n uses pure visualisation, not an LLM router”: deterministic first, LLM as fallback.
A reference implementation (rewritten on top of the FastAPI server skeleton from Part 05 of this series, not the production 1:1):
# router.py
from dataclasses import dataclass
from enum import Enum
class Mode(Enum):
FAST = "fast"
SAFE = "safe"
DEEP_EVAL = "deep_eval"
CREATIVE = "creative"
AGENTIC = "agentic"
def route(features: QueryFeatures, override: Mode | None = None) -> Mode:
# Ops escape hatch: request carries a mode to force-override
if override is not None:
return override
# Step 1: multi-step → agentic
if features.is_multi_step:
return Mode.AGENTIC
# Step 2: high domain risk → safe
if features.domain_risk == "high":
return Mode.SAFE
# Step 3: contract / legal + numeric constraints → safe
if features.has_numeric_constraints and features.source_path in {"contract", "legal"}:
return Mode.SAFE
# Step 4: summarisation + open source → creative
if features.intent_classifier == "summarization" and features.source_path == "open":
return Mode.CREATIVE
# Step 5: faq / runbook + short query → fast
if features.source_path in {"faq", "runbook"} and features.query_length < 50:
return Mode.FAST
# Step 6: everything else → safe (default strict)
return Mode.SAFE# /ask endpoint
@app.post("/ask")
async def ask(req: AskRequest):
features = extract_features(req.query, req.context) # cheap features first
if needs_llm_fallback(features):
features.intent_classifier = await llm_intent_classify(req.query) # one LLM call
mode = route(features, override=req.mode)
return await dispatch(mode, req) # each mode assembles its own pipeline + its own eval/traceA few implementation risks to know about before implementing:
-
The cost structure of
extract_featuresandllm_intent_classifyis project-specific — in the Part 05 skeleton,source_pathis already present in the document metadata (FAQ / runbook / contract are tagged in metadata), so it’s free; if you have to derivesource_pathvia LLM, the whole cost model has to be redone. -
If
domain_risk = "high"is derived directly fromsource_path(contract / legal / medical metadata tagged as high), it’s good enough; if you have to scan document contents for keywords, the false-positive rate goes up, and you need an offline dataset calibration pass first. -
override=req.modeshould not be exposed to every user. It is an ops escape hatch, not an end-user feature. Every override should write an audit log: who overrode it, what the original mode was, what it became, and what the route reason was. -
The router output should not be just a mode. It should include
route_reason,features_snapshot, andfallback_used. Without those three fields, routing failures are hard to replay.
Dispatch should not become a pile of if-else
After the mode router is written, the next trap is that dispatch(mode, req) easily becomes a pile of if-else. Five modes are manageable at first, but once SQL tools, long-context packing, and agentic workflows arrive, dispatch becomes the next tightly coupled layer.
A cleaner pattern is to turn mode into a pipeline config:
@dataclass
class PipelineConfig:
use_hybrid: bool
use_rerank: bool
use_parent_expansion: bool
citation_level: str # "off" / "weak" / "full" / "per_step"
faithfulness_level: str # "off" / "async" / "sync" / "per_step"
trace_level: str # "query" / "stage" / "full" / "per_step"
max_cost_usd: float
timeout_seconds: int
max_steps: int | None = None
allowed_tools: list[str] | None = NoneThen:
mode = route(features, override=req.mode)
pattern = choose_pattern(features)
config = build_pipeline_config(mode, pattern)
return await run_pipeline(config, req)The upside:
- mode logic and pipeline assembly stay separate
- SQL / long-context / agentic additions do not blow up the router
- config can be written directly into the trace
- CI can test the full chain:
query → features → mode → pattern → config
At this point, /ask starts to behave like a production router, not a demo endpoint with extra flags.
Where this post sits in the series
Part 08 turns the capabilities from Part 07 into runtime decisions.
- Part 06 answers: how do we retrieve better?
- Part 07 answers: how do we know the answer is grounded?
- Part 08 answers: when should a query pay for each of those capabilities?
- Part 09 moves to the document side: ingestion, metadata, ACL, document APIs, and citation viewer.
If reduced to one sentence:
Production RAG does not run the full pipeline for every query; it routes every query to the pipeline it deserves.
The query router is the system’s decision layer. Agentic RAG is what happens when the question can no longer be answered by “retrieve once, synthesize once”: the brain decomposes, calls tools, checks intermediate evidence, and still stays bounded.
Part 09 moves to the other side. If the query-time router is the decision layer, ingestion / metadata / ACL are the governance layer. Without that layer, even a strong router cannot guarantee that documents actually enter, stay governed, and stay queryable.