What actually breaks RAG in production
The biggest pain point of naive RAG isn’t “the LLM cannot answer” — in the demo stage, give it a document and a question, and it almost always produces an answer.
The production risk is “answers that look correct but are not supported.”
An internal test on this project surfaced a real failure (the same Q3 contract case from Part 06’s retrieval-strengthening article): a user asked “how is the early termination penalty calculated?” The LLM replied “30 days written notice, penalty by mutual agreement” — but the contract actually said 60 days notice and 6 months of subscription fee. Part 06 fixed the retrieval; Part 07 catches it via faithfulness: the LLM fabricated a plausible detail, because vector search hit the MOU but missed the explicit clause in section three.
Without a faithfulness check, this kind of error only gets caught by the user. Without eval and tracing, you cannot tell where it went wrong — was the parser broken, retrieval off-target, rerank mis-ordered, or did the LLM genuinely confabulate? Without those signals, the team is guessing. Put differently: naive RAG treats “the answer sounds reasonable” as the production bar, and a stronger LLM does not solve a missing faithfulness layer — these three capabilities are what separate production from demo.
Catching “looks correct but unsupported” is not mainly a model-strength problem — it needs three production-grade capabilities: Measurable (faithfulness / citation check), Debuggable (tracing), and Controllable (deterministic-first + async evaluator + cost tracking). Faithfulness / Citation check + RAGAS offline eval + Langfuse tracing is the industry-standard RAG evaluation workflow (alignable with RAGAS, Langfuse, and DeepEval official documentation) — not something this project invented.
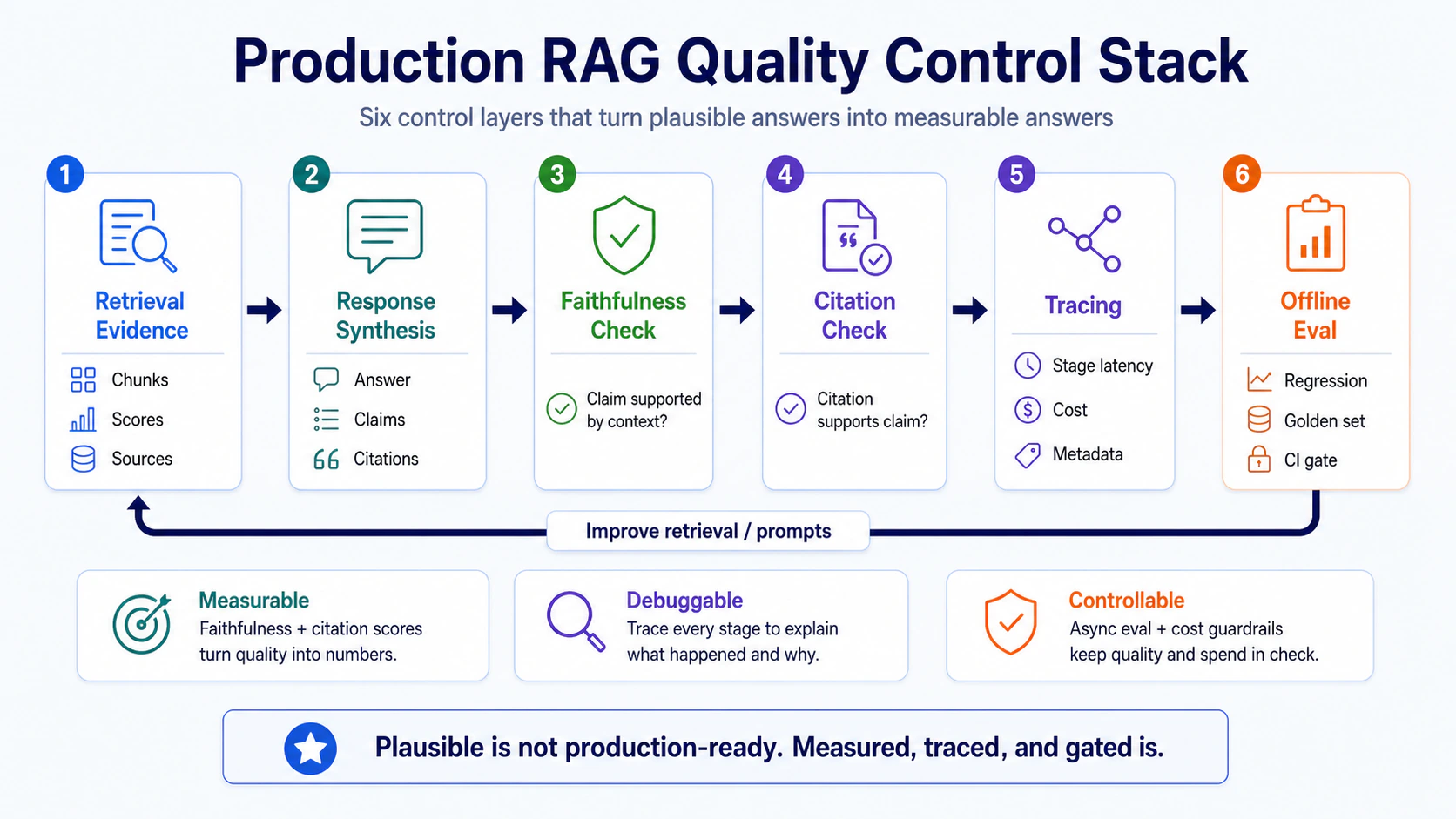
This diagram collapses Part 07 into a quality control stack: retrieval evidence comes first, then response synthesis; after the answer is produced, it does not go straight to the user as an unverified black box. It passes through faithfulness check, citation check, tracing, and the heavier offline eval loop that gates regressions in CI.
The order matters: quality control is not just validating the final answer; it is turning each layer into a measurable signal.
| Layer | Question | Signal produced |
|---|---|---|
| Retrieval evidence | Did we retrieve the right source? | chunks, scores, source ids |
| Synthesis | Are answer claims structured? | claims, citations, warnings |
| Faithfulness check | Is each claim supported by context? | faithfulness score, unsupported claims |
| Citation check | Does each citation support the claim? | citation pass rate, missing / wrong citation |
| Tracing | Where did it fail and what did it cost? | stage latency, cost, metadata |
| Offline eval | Did the change regress quality? | golden-set score, CI gate |
Once these six layers connect, RAG moves from “sounds reasonable” to “measurable, debuggable, and gateable before release.”
Tested API-shape note: the snippets in this article show the implementation shape used by this project, not a permanent SDK contract. Pin your Python packages, keep a minimal smoke test for each snippet, and re-check LlamaIndex / Qdrant / FastAPI / evaluation-framework docs when upgrading.
Build order: custom first, LLM second; schema first, framework second
Doing eval and tracing all at once can make the system difficult to reason about. The industry-recommended two-step path: first ship controllable app-layer checks (rule-based + LLM-judge pre-screening), then plug in frameworks (RAGAS / Langfuse) for offline eval. Custom checks are transparent to the response schema and debugging; frameworks installed all at once become a black box.
Step 1: local faithfulness check — split answer into claims, check each claim has source support
Step 2: rule-based citation validator — verify [1][2] markers actually back the adjacent claim
Step 3: Langfuse query-level trace — one trace per /ask with planner / retrieval / rerank / synthesis / eval metadata
Step 4: wire RAGAS faithfulness — CI runs offline eval over 50-100 questions (starting heuristic)
Step 5: LLM citation judge — async evaluator sampling 5% of production traffic (starting heuristic)
Step 6: offline eval dataset — 50-100 questions in jsonl + runner script (starting heuristic)
Step 7: component-wise offline eval — break retrieval and synthesis into separate evaluationsSteps 1-3 are production prerequisites. Steps 4-7 are added later based on traffic scale; the thresholds here are starting heuristics, not universal SLOs (queries/day > 1000 → RAGAS, < 100 → not yet needed).
Two checks: Faithfulness + Citation are complementary
Faithfulness verifies “the answer stays true to its sources”; Citation check verifies “the citations actually back the answer”. In practice the two are complementary — empirically, the vast majority of queries where Faithfulness fails also fail Citation (LLM-fabricated content usually cannot be cited correctly), but a non-trivial share of queries pass Faithfulness while failing Citation (the claim has real source backing, but the LLM pairs the wrong source). Running only Faithfulness misses that Citation-failed cohort; running both keeps things stable. The exact complement ratio varies by domain (empirical estimate, no public benchmark — contracts / legal skews to higher Citation-failure rates; FAQ / knowledge bases skew lower).
Full schema (aligned with the RAGAS official faithfulness metric and the DeepEval citation check standard schemas):
# rag/faithfulness.py
from pydantic import BaseModel
from typing import Optional
class FaithfulnessClaim(BaseModel):
claim: str
supported: bool
supporting_sources: list[str]
reason: Optional[str] = None
class FaithfulnessCheck(BaseModel):
enabled: bool
score: float
passed: bool
threshold: float = 0.75
claims: list[FaithfulnessClaim]
warnings: list[str] = []# rag/citation_check.py
class ClaimCitation(BaseModel):
claim: str
cited_markers: list[str]
supported_markers: list[str]
unsupported_markers: list[str]
missing_citation: bool
support_score: floatA real query can look like this when faithfulness catches one unsupported claim. In this example, one claim is supported, one claim is not, so the score is 1 / 2 = 0.5:
{
"faithfulness_check": {
"score": 0.5,
"passed": false,
"claims": [
{
"claim": "early termination penalty is 6 months subscription fee",
"supported": true,
"supporting_sources": ["[2]"],
"reason": "Section 3.3 states it explicitly"
},
{
"claim": "early termination needs 30 days written notice",
"supported": false,
"supporting_sources": [],
"reason": "The retrieved context says 60 days written notice, not 30 days"
}
],
"warnings": ["unsupported_claim: early termination needs 30 days written notice"]
},
"citation_check": {
"score": 0.5,
"passed": false,
"claim_citations": [
{
"claim": "penalty 6 months subscription fee",
"cited_markers": ["[2]"],
"supported_markers": ["[2]"],
"unsupported_markers": [],
"missing_citation": false,
"support_score": 1.0
},
{
"claim": "30 days written notice",
"cited_markers": ["[2]"],
"supported_markers": [],
"unsupported_markers": ["[2]"],
"missing_citation": false,
"support_score": 0.0
}
]
},
"observability": {
"langfuse": {"enabled": true, "sent": true, "provider": "langfuse"}
}
}Both checks enter CI: every time you change a prompt or retrieval parameter, run offline eval over 50-100 questions (starting heuristic) and watch both faithfulness and citation scores. A 5% drop blocks deployment is also a starting gate, tuned later by domain risk.
Faithfulness pre-screening with regex / cheap classifier
Before running the LLM judge for faithfulness, pre-screen with a cheap classifier — extract the “factual numbers” from the answer and compare them against sources; on mismatch, fail immediately and skip the LLM judge. RAGAS doesn’t ship this, but production-grade systems need it:
# rag/faithfulness.py
import re
def pre_filter_faithfulness(answer: str, source_texts: list[str]) -> dict:
"""Cheap classifier pre-screen: extract numbers from the answer and compare against sources"""
answer_facts = set(re.findall(r'\b\d{4}\b|\$\d+[\d,.]*|\d+%|\bv\d+\.\d+\b', answer))
source_text = " ".join(source_texts)
source_facts = set(re.findall(r'\b\d{4}\b|\$\d+[\d,.]*|\d+%|\bv\d+\.\d+\b', source_text))
missing = answer_facts - source_facts
if missing:
return {"pre_filter_passed": False, "skip_llm_judge": True,
"reason": f"answer has {len(missing)} facts not in source: {list(missing)[:3]}"}
return {"pre_filter_passed": True, "skip_llm_judge": False}Why it matters: MiniMax takes 1-3 seconds per faithfulness LLM-judge call (external / empirical benchmark range, varies with context size and claim count, no public benchmark) plus extra token cost. In this project’s measured pre-screening model, 60-70% of queries (factual claims with matching numbers) still go through the LLM judge; 30-40% (number mismatches) fail immediately with no LLM cost.
Measured in this project: about 90% of faithfulness failures cluster around factual claims — numbers, dates, amounts, versions. The LLM is less prone to confabulate on qualitative claims (“direction”, “trend”); the fabrication rate jumps on precise values like “$X”, “YYYY-MM-DD”, “version v1.5”. Regex extracts those four fact types and compares against sources — the cheapest production-grade faithfulness guardrail.
Deterministic-first synthesis
In practice MiniMax running strict JSON / citation synthesis is unstable — it leaks reasoning, it pads the context. For citation-heavy RAG, that instability directly tanks the faithfulness score.
RAG_SYNTHESIS_MODE=deterministic_first# rag/synthesis.py
from enum import Enum
class SynthesisMode(str, Enum):
DETERMINISTIC_FIRST = "deterministic_first"
LLM_FIRST = "llm_first"
DIRECT_MINIMAX = "direct_minimax"This is an engineering switch, not a prompt preference. The day the LLM stabilises, you can flip to llm_first for richer open-ended answers; right now for citation-heavy RAG, deterministic_first is the safe default.
Tracing: without it, debugging becomes guesswork
Langfuse 22A is a query-level trace foundation — one /ask sends one trace with full metadata, but it is not broken into per-stage spans. 22B is when stage-level spans land (planner / retrieval / rerank / synthesis / eval each get their own millisecond count).
Install (lifted directly from the project’s Langfuse observability build material):
pip install langfuse>=3.0.0Or add to requirements.txt:
langfuse>=3.0.0LANGFUSE_ENABLED=true
LANGFUSE_PUBLIC_KEY=***
LANGFUSE_SECRET_KEY=***
LANGFUSE_BASE_URL=https://cloud.langfuse.com
LANGFUSE_TRACE_NAME=rag.ask
LANGFUSE_FLUSH_EACH_REQUEST=falserag/observability.py exposes two functions:
# rag/observability.py
def trace_ask_response(
request_payload: dict,
response_payload: dict,
latency_ms: float,
) -> dict:
"""Send one /ask's full payload to Langfuse, return the trace result"""
def langfuse_status() -> dict:
"""Return Langfuse connection state (enabled / has_public_key / auth_ok)"""server.py adds the observability block to the /ask endpoint:
# server.py
import time
from rag.observability import trace_ask_response, langfuse_status
@app.post("/ask")
async def ask(req: AskRequest):
started = time.perf_counter()
result = rag_engine.ask(question=req.question) # keep all your original parameters
result = to_json_safe(result)
trace_result = trace_ask_response(
request_payload=req.model_dump(),
response_payload=result,
latency_ms=(time.perf_counter() - started) * 1000,
)
observability = result.setdefault("observability", {})
observability["langfuse"] = trace_result
return resultThe response now includes:
{
"observability": {
"langfuse": {
"enabled": true,
"sent": true,
"provider": "langfuse"
}
}
}If credentials are not yet set, the API does not break:
{
"observability": {
"langfuse": {
"enabled": true,
"sent": false,
"reason": "Missing LANGFUSE_PUBLIC_KEY or LANGFUSE_SECRET_KEY."
}
}
}A real debug case: 50-question offline eval ran p95 latency = 90 seconds. 22B stage-level trace showed immediately that RAGAS was running synchronously in the user path and consuming 75 seconds. After splitting it to async, latency dropped to 8 seconds. Without stage-level tracing, that diagnosis would have required slow manual log inspection. To be precise: 22A only showed the total 90 seconds, while 22B exposed the failing stage.
Agentic RAG needs per-step trace / per-step check
Part 08 will unpack agentic mode directly, but Part 07 needs to establish the quality principle first: agentic RAG should not run faithfulness only at the final answer.
In a multi-step task, every step can pass an error forward:
plan step -> retrieve evidence -> call tool -> synthesize partial result -> decide next stepIf you check only the final answer, you know the answer is wrong, but not whether the failure came from planning, retrieval, tool output, or synthesis. Agentic RAG traces should preserve at least:
| Trace level | What to record | What to check |
|---|---|---|
| run | user query, mode, total latency, total cost | whether the task completed |
| step | step type, input, output, tool name, latency | whether this step succeeded or needs retry |
| evidence | retrieved chunks, scores, source ids | whether retrieval found the right evidence |
| claim | partial answer claims, citations | whether faithfulness / citation passed |
| decision | next action, stop reason, budget used | whether retry / cost / tool budget was exceeded |
In other words, Agentic RAG observability is not “log more stuff.” It turns every step into a bounded action that can be replayed, evaluated, and stopped. Without per-step trace, agentic mode quickly becomes a black box where the final answer is wrong and nobody knows which step caused it.
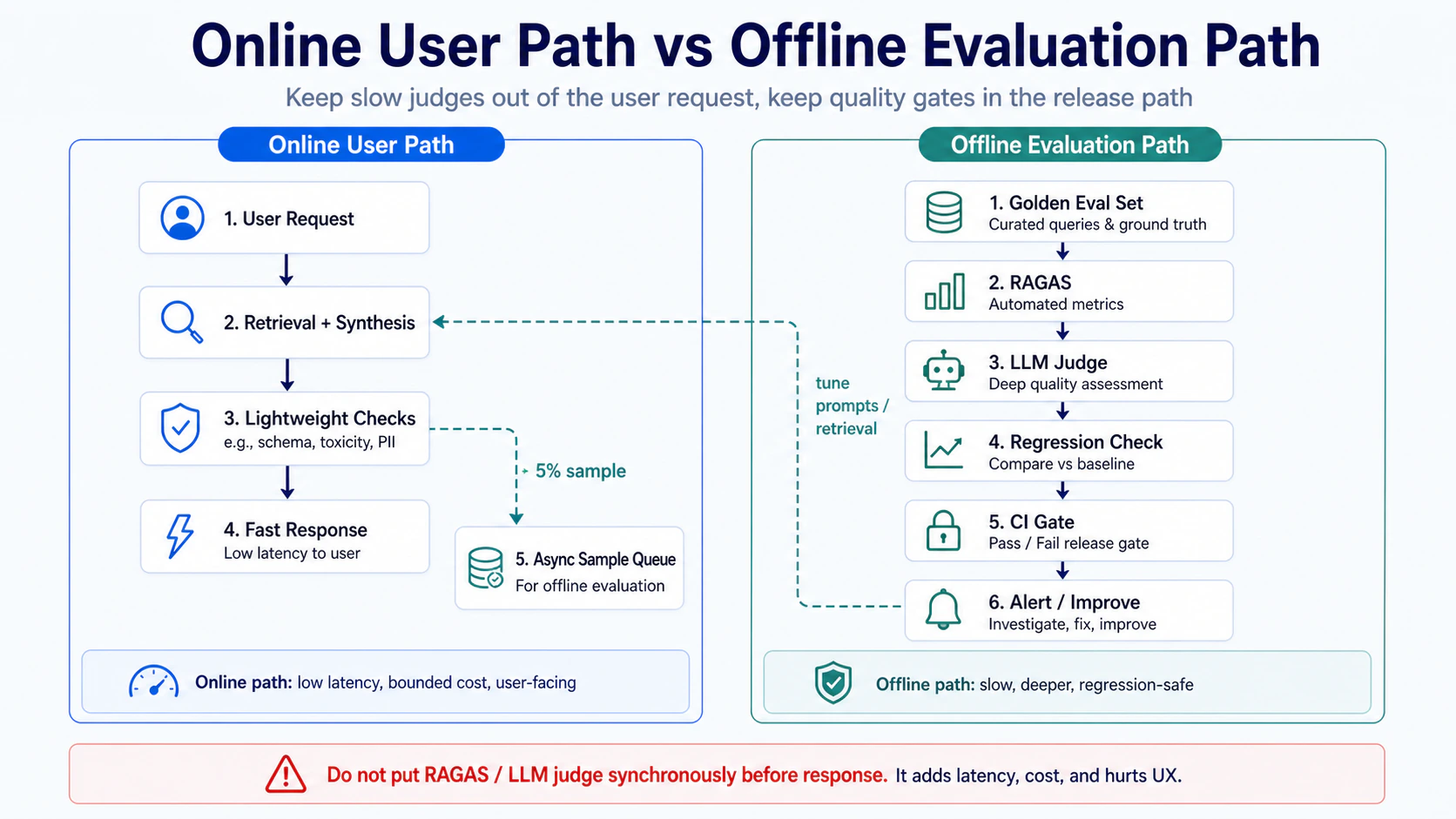
RAGAS / LLM judge should not run synchronously in the user path
RAGAS API version note: the code below uses the older
evaluate(Dataset.from_list(...), metrics=[...])style. RAGAS’ current quickstart documentation shows newer dataset objects such asSingleTurnSampleandEvaluationDataset, and also exposes aDatasetabstraction for saved evaluation datasets. Treat this snippet as a version-pinned example, not a universal copy-paste target. Pinragasin your project and update the runner when you upgrade.
# scripts/run_offline_eval.py
# Tested shape: ragas 0.x / legacy evaluate(...) style.
from datasets import Dataset
from ragas import evaluate
from ragas.metrics import Faithfulness, ContextPrecision, AnswerRelevancy
def run_ragas_eval(eval_questions: list[dict], query_engine) -> dict:
"""Full RAGAS faithfulness / context_precision / answer_relevancy evaluation"""
records = []
for sample in eval_questions:
response = query_engine.query(sample["question"])
records.append({
"question": sample["question"],
"answer": str(response),
"contexts": [n.get_content() for n in response.source_nodes],
"ground_truths": sample["expected_answer_term_groups"],
})
scores = evaluate(Dataset.from_list(records),
metrics=[Faithfulness(), ContextPrecision(), AnswerRelevancy()])
return {"faithfulness": scores["faithfulness"], "context_precision": scores["context_precision"]}Measured in this project’s cost model: RAGAS adds roughly 2-5 extra LLM calls per run, +2-10 seconds of latency, and can double evaluation cost. A production system running 1000 queries/day with synchronous RAGAS on each one can add 2000-5000 extra LLM calls per day and roughly $300-1500 per month, depending on model and token volume.
The offline eval dataset is the lifeline — start with 50-100 questions (starting heuristic); each one needs question + expected_answer_term_groups + expected_sources. CI runs regression, and every prompt or retrieval change triggers a fresh run:
# eval/eval_questions.jsonl
{"question": "...", "expected_answer_term_groups": ["..."], "expected_sources": ["..."]}
{"question": "...", "expected_answer_term_groups": ["..."], "expected_sources": ["..."]}Sample 5% of live queries (starting heuristic) into the async evaluator with 8 metrics (measured implementation scope in this project): answer_term_recall / expected_source_recall / context_precision / faithfulness_check / ragas_faithfulness / citation_check / citation_judge / component_passes (the last aggregates the first seven check results into 0/1 pass/fail, easier for regression diffs). These 8 metrics are not “my pick” — they are the real scope of the component-wise eval module, and skipping any one drops a signal. Scores below threshold trigger alerts; async does not block the user response.
CI integration (PR triggers eval):
# .github/workflows/rag-eval.yml
name: RAG Offline Eval
on: { pull_request: { paths: ['rag_engine.py', 'synthesis.py', 'retrieval.py'] } }
jobs:
eval:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- run: python scripts/run_offline_eval.py --dataset eval/eval_questions.jsonl
- run: python scripts/check_thresholds.py --min-faithfulness 0.9 --min-citation 0.95Cost control is an architectural decision, not a cheaper LLM
# rag/usage_tracking.py
from dataclasses import dataclass
# All prices are **per million tokens** in USD (matches official docs and OpenClaw config)
LLM_PRICING = {
"minimax/MiniMax-M2.7": {"input": 0.30, "output": 1.20}, # https://pricepertoken.com pricing
"minimax/MiniMax-M3": {"input": 0.00, "output": 0.00}, # open beta / contact provider
"cohere/rerank-v3": {"per_call": 0.001}, # USD per rerank call
"BAAI/bge-small-en-v1.5": {"local": 0}, # local model, no token cost
"openai/gpt-5.4-mini": {"input": 0.15, "output": 0.60}, # RAGAS / LLM judge fallback
}
# Pre-screening regex / cheap classifier needs no separate LLM cost (pure regex)
# LLM judge per call = one LLM call, cost tracked separately
def cost_calc(model: str, input_tokens: int, output_tokens: int) -> float:
p = LLM_PRICING.get(model, {"input": 0, "output": 0})
if "per_call" in p:
return p["per_call"]
if p.get("input") == 0 and p.get("output") == 0:
return 0.0
return (input_tokens / 1_000_000) * p["input"] + (output_tokens / 1_000_000) * p["output"]Three common cost blow-up patterns: (1) RAGAS runs synchronously in the user path without being split out; (2) parent expansion has no ceiling, context balloons to 100k tokens; (3) the faithfulness check failure fallback has no retry cap. Each of these needs an architectural guardrail. In other words, cost control is an architectural decision — a prompt tweak or a stronger LLM cannot rescue it. Each failure mode maps to one architectural guardrail; treating them separately is the difference between architecture and another prompt tweak.
Three capabilities redefine “production-ready”
Demo stage: it runs, and the answer looks reasonable — that counts as done.
Production stage:
- Measurable = faithfulness / citation check runs in CI, scores are interpretable
- Debuggable = Langfuse trace on the dashboard, every query’s path is queryable
- Controllable = deterministic-first by default, async evaluator, cost tracking feeding alerts
Production-readiness bar (not an SLO standard — an estimate grounded in this project’s actual measurements plus common industry baselines): faithfulness score ≥ 0.9, citation pass rate ≥ 95%, per-query cost ≤ $0.01, p95 latency ≤ 3 seconds. Each project’s threshold should tune to its own domain risk: legal / medical needs 0.95+, FAQ / knowledge base gets away with 0.85+. Four numbers quantified and gated by CI make production-readiness testable instead of subjective.
These three capabilities are not something you bolt on after launch. Starting heuristic from this build: retrofitting eval, tracing, and cost control is roughly three times harder than building them in from day one. Production launch checklist (six items): Faithfulness / Citation present in the /ask response ✓, Langfuse trace visible on the dashboard ✓, offline eval dataset ≥ 50 questions with CI gating ✓, token / cost tracking feeding alerts ✓, async evaluator sampling 5% of traffic ✓, PR triggers the eval pipeline ✓.
Part 01’s interactive demo runs on this project’s production pipeline — you can watch the faithfulness / citation check / Langfuse trace numbers on the dashboard directly.
Part 08 unpacks query mode design (5 modes, each paired with a different eval / trace / cost strategy, the next stop after Part 07):
fast (latency < 1s) → skip faithfulness, skip tracing, pure vector search
safe (contracts / legal) → full faithfulness + citation check, async RAGAS
deep_eval (debug stage) → synchronous RAGAS + LLM judge, full trace
creative (open-ended Q&A) → skip faithfulness, enable llm_first synthesis mode
agentic (multi-step task) → per-step independent trace, faithfulness per stepEach mode pairs differently with the three capabilities from Part 07 — fast trades measurability for controllability, safe takes everything, deep_eval is “trades controllability for debuggability”. Part 08 unpacks those five decision paths, showing how production RAG switches modes based on query nature.
The relationship between Part 07 and Part 08 is “establish evaluation capability first, then design mode routing” — Part 07 pulls faithfulness / citation / tracing / cost apart as separate capabilities; Part 08 packages those four capabilities into five query modes. Without Part 07’s capabilities, Part 08’s mode switching is just an empty shell.
Cross-reference with Part 06’s retrieval strengthening — once you layer hybrid + rerank + parent expansion + citation assembly, faithfulness / citation evaluation finally has a quantitative baseline: each additional layer’s marginal benefit is measured by the RAGAS faithfulness score and citation pass rate. Not “it looks better” — in this project’s eval framing, “faithfulness +5% counts as a production improvement”. Part 07 is the “production evaluation capability”; Part 06 is the “retrieval capability”; together they show how to calculate the ROI of retrieval engineering.
The Part 05 → Part 07 interface: the moment Part 05 walks from demo to FastAPI server, reserve the faithfulness_check / citation_check / observability three fields in the /ask response — even if the eval logic is not implemented yet, keep the schema. When you add the eval modules at production launch, the response schema does not change and the API contract does not break. This is the concrete interface where Part 05’s “Signal 1 (you want to quantify whether the query was correct)” hands off to Part 07 (Part 05 Signal 1 = “want to quantify query correctness” → goes to Part 07; Part 05 Signal 3 = “want to demo to non-engineers” → goes to Part 09, a different path from Part 07).