RAG 最怕的不是答不出來
naive RAG 最大的痛點不是「LLM 答不出問題」——demo 階段你給它一份文件、問一個問題,它幾乎一定答得出來。
RAG 最怕的是「看起來對、但其實不對」。
這個專案內部測試時發生過一次(跟 Part 06 retrieval 強化裡講的同一個 Q3 合約案例):使用者問「early termination 違約金怎麼算」,LLM 答「30 天書面通知、違約金由雙方協商」——但合約寫的是 60 天通知、6 個月訂閱費。Part 06 修 retrieval,Part 07 抓 faithfulness:LLM 編造了一個合理的細節,vector search 撈到 MOU 但沒撈到第三段明確條款。
沒裝 faithfulness check 之前,這類錯誤只能靠使用者自己抓。沒裝 eval 跟 tracing 之前,錯了也不知道錯在哪——是 parser 切壞、retrieval 撈錯、rerank 排錯、還是 LLM 真的腦補?靠猜。換個角度講:naive RAG 把「答案看起來合理」當 production 標準,LLM 換成更強的也救不回 faithfulness 失敗——這 3 個能力才是 production 跟 demo 的差距。
把「看起來對、其實不對」這類錯誤壓下來,需要的不是更強的 LLM——是 3 個 production 級能力:可量測(faithfulness / citation check)、可除錯(tracing)、可控(deterministic-first + async evaluator + cost tracking)。Faithfulness / Citation check + RAGAS offline eval + Langfuse tracing 是業界 RAG 評估的標準流程(從 RAGAS、Langfuse、DeepEval 官方文件可對齊),不是這個專案自創。
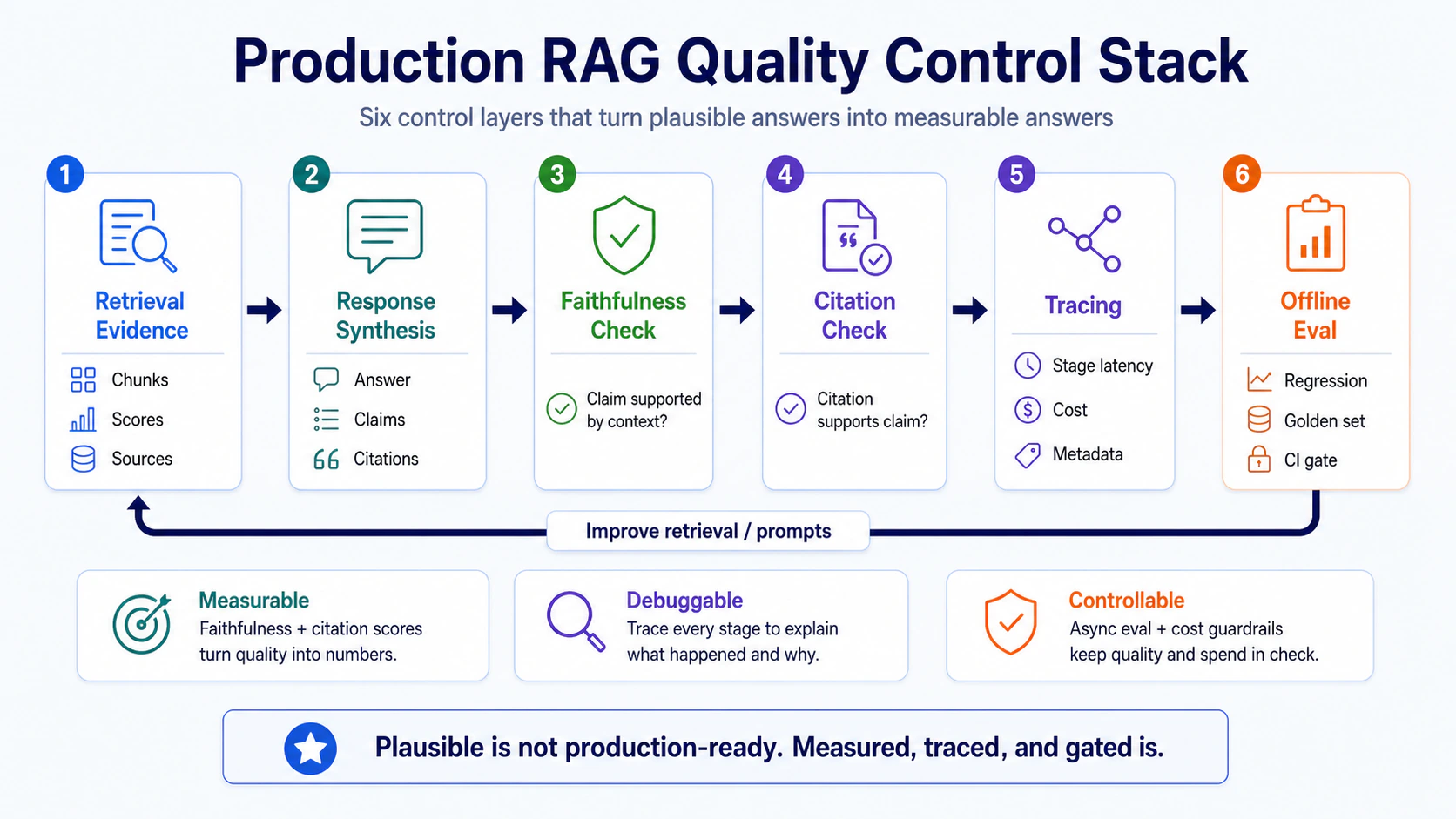
這張圖把 Part 07 的主題收成一個 quality control stack:先有 retrieval evidence,才有 response synthesis;答案產生後,不是直接交給 user,而是經過 faithfulness check、citation check、tracing,再把更重的 offline eval 放進回歸與 CI。
這裡有一個很重要的順序:quality control 不是只在最後驗答案,而是把每一層都變成可量測訊號。
| 層 | 問的問題 | 產生的訊號 |
|---|---|---|
| Retrieval evidence | 有沒有撈到正確 source? | chunks、scores、source ids |
| Synthesis | answer claim 有沒有結構化? | claims、citations、warnings |
| Faithfulness check | claim 是否被 context 支撐? | faithfulness score、unsupported claims |
| Citation check | citation 是否真的支撐 claim? | citation pass rate、missing / wrong citation |
| Tracing | 錯在哪一段、花多少錢? | stage latency、cost、metadata |
| Offline eval | 改動有沒有 regression? | golden-set score、CI gate |
把這 6 層串起來,RAG 才從「看起來合理」變成「可以被測、可以被 debug、可以被阻擋上線」。
Tested API shape 提醒:本文程式片段示範的是這個專案採用的實作形狀,不是永久不變的 SDK contract。請 pin Python 套件版本,替每段關鍵 snippet 保留最小 smoke test,升級 LlamaIndex / Qdrant / FastAPI / eval framework 前先對照官方文件。
建構順序:先 custom 再 LLM,先 schema 再接 framework
Eval / tracing 一次到位會爆炸。業界推薦兩步走:先做可控的 app-layer check(rule-based + LLM-judge 預篩),再接 framework(RAGAS / Langfuse)做 offline eval。custom check 對 response schema 跟 debugging 都透明;framework 一次塞太多會變黑盒。
Step 1:local faithfulness check —— 拆 answer 成 claims,檢查每個 claim 是否有 source 撐
Step 2:rule-based citation validator —— 比對 [1][2] marker 是否真的支持 claim
Step 3:Langfuse query-level trace —— 每筆 /ask 留下 planner / retrieval / rerank / synthesis / eval 全鏈 trace
Step 4:接 RAGAS faithfulness —— CI 跑 offline eval 50-100 題(起步 heuristic)
Step 5:LLM citation judge —— async evaluator,5% 抽樣 production traffic(起步 heuristic)
Step 6:offline eval dataset —— 50-100 題 jsonl + runner script(起步 heuristic)
Step 7:component-wise offline eval —— 拆 retrieval / synthesis 各自評估Step 1-3 production 必須先做,Step 4-7 之後按 traffic 規模補;這裡的門檻是起步 heuristic,不是通用 SLO(queries/day > 1000 該上 RAGAS、< 100 還不需要)。
兩次檢查:Faithfulness + Citation 互相補強
Faithfulness 檢查「答案有沒有忠於來源」,Citation check 檢查「引用是否真的支持答案」。兩道互補——常見經驗是 Faithfulness 失敗的 query 裡絕大多數也伴隨 Citation 失敗(LLM 編造的內容引不到 source),但有相當比例 Faithfulness 過、Citation 失敗(claim 有 source 撐,但 LLM 拉錯 source 配對)。單跑 Faithfulness 會漏 Citation 失敗,兩道一起跑才穩。具體比例依 domain 而異(經驗估算、無公開基準——合約 / 法律 Citation 失敗率偏高,FAQ 偏低)。
完整 schema(從 RAGAS / DeepEval 標準 schema 對齊):
# rag/faithfulness.py
from pydantic import BaseModel
from typing import Optional
class FaithfulnessClaim(BaseModel):
claim: str
supported: bool
supporting_sources: list[str]
reason: Optional[str] = None
class FaithfulnessCheck(BaseModel):
enabled: bool
score: float
passed: bool
threshold: float = 0.75
claims: list[FaithfulnessClaim]
warnings: list[str] = []# rag/citation_check.py
class ClaimCitation(BaseModel):
claim: str
cited_markers: list[str]
supported_markers: list[str]
unsupported_markers: list[str]
missing_citation: bool
support_score: float真實 query 可能長這樣:faithfulness 抓出 1 個 unsupported claim。這個例子裡 2 個 claim 有 1 個被 source 支持、1 個不被支持,所以 score = 1 / 2 = 0.5:
{
"faithfulness_check": {
"score": 0.5,
"passed": false,
"claims": [
{
"claim": "early termination 違約金是 6 個月訂閱費",
"supported": true,
"supporting_sources": ["[2]"],
"reason": "Section 3.3 明寫"
},
{
"claim": "early termination 需 30 天書面通知",
"supported": false,
"supporting_sources": [],
"reason": "retrieved context 寫的是 60 天書面通知,不是 30 天"
}
],
"warnings": ["unsupported_claim: early termination 需 30 天書面通知"]
},
"citation_check": {
"score": 0.5,
"passed": false,
"claim_citations": [
{
"claim": "違約金 6 個月訂閱費",
"cited_markers": ["[2]"],
"supported_markers": ["[2]"],
"unsupported_markers": [],
"missing_citation": false,
"support_score": 1.0
},
{
"claim": "30 天書面通知",
"cited_markers": ["[2]"],
"supported_markers": [],
"unsupported_markers": ["[2]"],
"missing_citation": false,
"support_score": 0.0
}
]
},
"observability": {
"langfuse": {"enabled": true, "sent": true, "provider": "langfuse"}
}
}兩道檢查進 CI:每次改 prompt / retrieval 參數都跑 offline eval 50-100 題(起步 heuristic),faithfulness 跟 citation 兩個分數都看。分數掉 5% 就 block 部署也是起步門檻,之後要按 domain 風險調整。
Faithfulness 預篩用 regex / cheap classifier
跑 LLM judge 評 faithfulness 之前,先用 cheap classifier 預篩——抓答案裡的「事實性數字」跟 source 對比,數字不一致直接 fail、跳過 LLM judge。這是 RAGAS 沒寫但 production 必須的護欄:
# rag/faithfulness.py
import re
def pre_filter_faithfulness(answer: str, source_texts: list[str]) -> dict:
"""Cheap classifier 預篩:抓 answer 裡的數字跟 source 對比"""
answer_facts = set(re.findall(r'\b\d{4}\b|\$\d+[\d,.]*|\d+%|\bv\d+\.\d+\b', answer))
source_text = " ".join(source_texts)
source_facts = set(re.findall(r'\b\d{4}\b|\$\d+[\d,.]*|\d+%|\bv\d+\.\d+\b', source_text))
missing = answer_facts - source_facts
if missing:
return {"pre_filter_passed": False, "skip_llm_judge": True,
"reason": f"answer 有 {len(missing)} 個 facts 不在 source: {list(missing)[:3]}"}
return {"pre_filter_passed": True, "skip_llm_judge": False}為什麼重要:MiniMax 跑 faithfulness LLM judge 每次 1-3 秒(外部 / 經驗 benchmark 範圍,視 context size + claim 數量而異,無公開 benchmark)+ 額外 token 成本。以這個專案的預篩模型量測,60-70% 的 query(事實性 claim 數字一致)走 LLM judge、30-40%(數字不一致)直接 fail 不花 LLM 成本。
專案實測:faithfulness 失敗約 90% 集中在「數字 / 時間 / 金額 / 版本」這四種事實性 claim——LLM 對「$X」「YYYY-MM-DD」「版本 v1.5」這種精確值編造率明顯較高。regex 抓這四類事實、跟 source 比對——是 production 級最便宜的 faithfulness 護欄。
Deterministic-first synthesis
實務上發現 MiniMax 跑 strict JSON / citation synthesis 容易不穩——會輸出 reasoning、會多加 context。對 citation-heavy RAG,這種不穩直接影響 faithfulness 分數。
RAG_SYNTHESIS_MODE=deterministic_first# rag/synthesis.py
from enum import Enum
class SynthesisMode(str, Enum):
DETERMINISTIC_FIRST = "deterministic_first"
LLM_FIRST = "llm_first"
DIRECT_MINIMAX = "direct_minimax"這是工程開關不是 prompt 偏好。哪天 LLM 升級穩了可以切 llm_first 拿更好開放式回答,現在對 citation-heavy RAG deterministic_first 是安全預設。
Tracing:trace 沒裝就拜 AI 神明
Langfuse 22A 是** query-level trace 基準設施**——一次 /ask 送一筆 trace、含完整 metadata,但不拆成各 stage 的 span。22B 才做 stage-level span(拆成 planner / retrieval / rerank / synthesis / eval 各花多少 ms)。
裝法(從專案 Langfuse observability 這段開發素材 1:1 來):
pip install langfuse>=3.0.0或加到 requirements.txt:
langfuse>=3.0.0LANGFUSE_ENABLED=true
LANGFUSE_PUBLIC_KEY=***
LANGFUSE_SECRET_KEY=***
LANGFUSE_BASE_URL=https://cloud.langfuse.com
LANGFUSE_TRACE_NAME=rag.ask
LANGFUSE_FLUSH_EACH_REQUEST=falserag/observability.py 提供兩個函式:
# rag/observability.py
def trace_ask_response(
request_payload: dict,
response_payload: dict,
latency_ms: float,
) -> dict:
"""把一次 /ask 的完整 payload 送到 Langfuse,return trace 結果"""
def langfuse_status() -> dict:
"""回傳 Langfuse 連線狀態(enabled / has_public_key / auth_ok)"""server.py 在 /ask endpoint 加 observability 區塊:
# server.py
import time
from rag.observability import trace_ask_response, langfuse_status
@app.post("/ask")
async def ask(req: AskRequest):
started = time.perf_counter()
result = rag_engine.ask(question=req.question) # 保留你原本所有參數
result = to_json_safe(result)
trace_result = trace_ask_response(
request_payload=req.model_dump(),
response_payload=result,
latency_ms=(time.perf_counter() - started) * 1000,
)
observability = result.setdefault("observability", {})
observability["langfuse"] = trace_result
return resultResponse 會多出:
{
"observability": {
"langfuse": {
"enabled": true,
"sent": true,
"provider": "langfuse"
}
}
}若 credentials 還沒設好,也不會炸 API:
{
"observability": {
"langfuse": {
"enabled": true,
"sent": false,
"reason": "Missing LANGFUSE_PUBLIC_KEY or LANGFUSE_SECRET_KEY."
}
}
}真實 debug 案例:50 題 offline eval p95 latency = 90 秒。22B stage-level trace 一秒看出是 RAGAS 同步跑在 user path 佔 75 秒,async 拆開就降到 8 秒。沒 trace 之前這個 90 秒要怎麼追?用終端機 log 一行一行看?這是「trace 沒裝就拜 AI 神明」的真實案例——準確說,是「沒有 22B stage-level trace 就拜 AI 神明」;22A 只能看到總 latency 90 秒、看不到哪一段。
Agentic RAG 要做 per-step trace / per-step check
Part 08 會把 agentic mode 拆開講,但 Part 07 先要把品質觀念講清楚:agentic RAG 不能只在最後一步做 faithfulness check。
多步任務裡,每一步都可能把錯誤傳給下一步:
plan step → retrieve evidence → call tool → synthesize partial result → decide next step如果只檢查 final answer,你只知道最後答案錯,卻不知道是 plan 錯、retrieval 錯、tool output 錯,還是 synthesis 錯。Agentic RAG 的 trace 應該至少保留:
| Trace level | 要記什麼 | 要檢查什麼 |
|---|---|---|
| run | user query、mode、total latency、total cost | 這次任務是否完成 |
| step | step type、input、output、tool name、latency | 這一步是否成功、是否需要 retry |
| evidence | retrieved chunks、scores、source ids | retrieval 是否找對 evidence |
| claim | partial answer claims、citations | faithfulness / citation 是否通過 |
| decision | next action、stop reason、budget used | 是否超出 retry / cost / tool budget |
換句話說,Agentic RAG 的 observability 不是「多記一點 log」,而是把每一步都變成可回放、可評估、可停止的 bounded action。沒有 per-step trace,agentic mode 很快會變成一個答錯也不知道哪一步錯的黑盒。
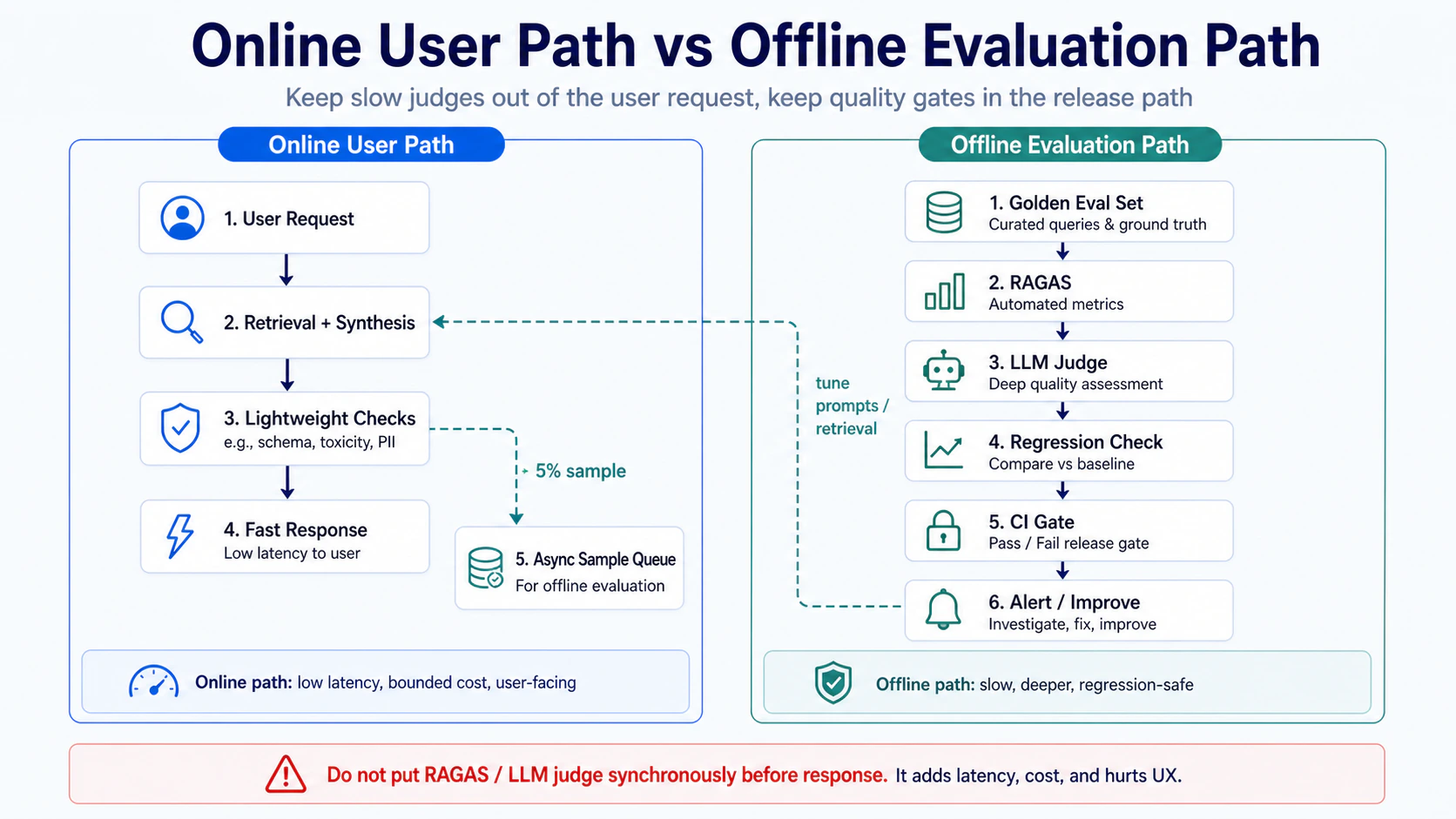
RAGAS / LLM judge 不該在 user path 同步跑
RAGAS API 版本提醒:下面這段用的是較舊的
evaluate(Dataset.from_list(...), metrics=[...])寫法。RAGAS 目前 quickstart 文件已經示範較新的 dataset objects,例如SingleTurnSample、EvaluationDataset,也有Datasetabstraction 給儲存式 eval dataset。這段應該視為 version-pinned example,不是永遠可直接複製的通用寫法。專案裡要 pinragas版本,升級時同步更新 runner。
# scripts/run_offline_eval.py
# Tested shape: ragas 0.x / legacy evaluate(...) style.
from datasets import Dataset
from ragas import evaluate
from ragas.metrics import Faithfulness, ContextPrecision, AnswerRelevancy
def run_ragas_eval(eval_questions: list[dict], query_engine) -> dict:
"""完整 RAGAS faithfulness / context_precision / answer_relevancy 評估"""
records = []
for sample in eval_questions:
response = query_engine.query(sample["question"])
records.append({
"question": sample["question"],
"answer": str(response),
"contexts": [n.get_content() for n in response.source_nodes],
"ground_truths": sample["expected_answer_term_groups"],
})
scores = evaluate(Dataset.from_list(records),
metrics=[Faithfulness(), ContextPrecision(), AnswerRelevancy()])
return {"faithfulness": scores["faithfulness"], "context_precision": scores["context_precision"]}以這個專案的 cost model 估算,RAGAS 每次跑要 2-5 次額外 LLM call、latency +2-10 秒、cost 可能翻倍。production 系統跑 1000 queries/day 都加 RAGAS 同步 = 每天多 2000-5000 次 LLM call、月成本多 $300-1500。
Offline eval dataset 是命脈——50-100 題起步(起步 heuristic),每題要有 question + expected_answer_term_groups + expected_sources,CI 跑 regression,每次改 prompt / retrieval 參數都跑一輪:
# eval/eval_questions.jsonl
{"question": "...", "expected_answer_term_groups": ["..."], "expected_sources": ["..."]}
{"question": "...", "expected_answer_term_groups": ["..."], "expected_sources": ["..."]}抽 5% live query(起步 heuristic)跑 async evaluator + 8 metrics(這 8 個是本專案 component-wise offline eval 的實作範圍):answer_term_recall / expected_source_recall / context_precision / faithfulness_check / ragas_faithfulness / citation_check / citation_judge / component_passes(把前 7 個 check 結果彙整成 0/1 pass/fail,便於 regression diff)。8 個 metrics 跟 component-wise eval 模組實作範圍 1:1,少裝哪一個都會漏 signal。分數低於 threshold 觸發 alert,async 不阻塞 user response。
CI 整合(PR 觸發 eval):
# .github/workflows/rag-eval.yml
name: RAG Offline Eval
on: { pull_request: { paths: ['rag_engine.py', 'synthesis.py', 'retrieval.py'] } }
jobs:
eval:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- run: python scripts/run_offline_eval.py --dataset eval/eval_questions.jsonl
- run: python scripts/check_thresholds.py --min-faithfulness 0.9 --min-citation 0.95成本控制:架構決策不是挑便宜 LLM
# rag/usage_tracking.py
from dataclasses import dataclass
# 全部 price 單位都是 **per million tokens** USD(跟官網 / OpenClaw config 一致)
LLM_PRICING = {
"minimax/MiniMax-M2.7": {"input": 0.30, "output": 1.20}, # https://pricepertoken.com 報價
"minimax/MiniMax-M3": {"input": 0.00, "output": 0.00}, # open beta / contact provider
"cohere/rerank-v3": {"per_call": 0.001}, # USD per rerank call
"BAAI/bge-small-en-v1.5": {"local": 0}, # 本地模型不計 token
"openai/gpt-5.4-mini": {"input": 0.15, "output": 0.60}, # RAGAS / LLM judge fallback
}
# 預篩 regex / cheap classifier 不需另計 LLM 成本(純 regex 運算)
# LLM judge 每次跑 = 一次 LLM call,成本另計
def cost_calc(model: str, input_tokens: int, output_tokens: int) -> float:
p = LLM_PRICING.get(model, {"input": 0, "output": 0})
if "per_call" in p:
return p["per_call"]
if p.get("input") == 0 and p.get("output") == 0:
return 0.0
return (input_tokens / 1_000_000) * p["input"] + (output_tokens / 1_000_000) * p["output"]成本失控 3 個常見模式:(1) RAGAS 同步跑 user path 沒拆掉;(2) parent expansion 沒節制、context 塞 10 萬 token;(3) faithfulness check 失敗 fallback 沒設上限。每一個都要在架構層設護欄——cost control 是架構決策,prompt 改、LLM 升級都救不回,拆開看才是真架構。
3 個能力重新定義「可上線」
Demo 階段:跑得起來、答案看起來合理就算完成。
Production 階段:
- 可量測 = faithfulness / citation check 在 CI 跑、score 要看得懂
- 可除錯 = Langfuse trace 在 dashboard 上、每個 query 走過哪些節點都查得到
- 可控 = deterministic-first 預設、async evaluator、cost tracking 進 alert
可上線的判準(不是 SLO 標準——是根據這個專案實際測量 + 常見業界基準的估算):faithfulness 分數 ≥ 0.9、citation pass rate ≥ 95%、每 query 成本 ≤ $0.01、p95 latency ≤ 3 秒。每個專案的 threshold 應該按 own domain 風險調:法律 / 醫療領域要 0.95+、FAQ / 知識庫 0.85+ 就夠。4 個數字有量化、進 CI 守門,缺一個都還沒到 production。
這 3 個能力不是 launch 之後再補。以這次 build 的起步 heuristic 來看,Retrofit eval / tracing / cost control 比一開始就建難約 3 倍。Production launch 前 checklist(6 件):Faithfulness / Citation 在 /ask response 裡 ✓、Langfuse trace 在 dashboard 上 ✓、Offline eval dataset ≥ 50 題 + CI 守門 ✓、Token / cost tracking 進 alert ✓、Async evaluator 5% 抽樣 ✓、PR 觸發 eval pipeline ✓。
Part 01 的互動 demo 跑的就是這個專案的 production pipeline——你可以直接看 faithfulness / citation check / Langfuse trace 在 dashboard 上的數字。
Part 08 拆 query mode 設計(5 種 mode 各自搭配不同 eval / trace / cost 策略,是 Part 07 的下一站):
fast (latency < 1s) → skip faithfulness、skip tracing、純 vector search
safe (合約/法律) → full faithfulness + citation check、async RAGAS
deep_eval (debug 階段) → 同步跑 RAGAS + LLM judge、full trace
creative (開放式問答) → skip faithfulness、開 llm_first synthesis mode
agentic (多步任務) → 每步獨立 trace、faithfulness 對每步都跑每種 mode 跟 Part 07 講的 3 個能力搭配方式不同——fast 犧牲可量測換可控、safe 全部都要、deep_eval 是「為了可除錯犧錯可控」。Part 08 會把這 5 條決策路徑拆清楚,告訴你 production RAG 怎麼根據 query 性質切換。
Part 07 跟 Part 08 的關係是「先建立評估能力,再設計 mode 路由」——Part 07 把 faithfulness / citation / tracing / cost 4 個 capability 拆開各自實作,Part 08 才把這 4 個 capability 包成 5 種 query mode。沒有 Part 07 的能力,Part 08 的 mode 切換就只是空殼。
順帶看 Part 06 講的 retrieval 強化——hybrid + rerank + parent expansion + citation assembly 4 層加上去後,faithfulness / citation 評估才有量化基準:4 層強化每加一層的邊際效益,用 RAGAS 跑出來的 faithfulness 分數跟 citation pass rate 來量;不是「看起來都對」、而是在這個專案的 eval framing 裡,「faithfulness +5% 算 production 改進」。Part 07 是「production 評估能力」,Part 06 是「retrieval 能力」,兩個一起看才知道 retrieval engineering 的 ROI 怎麼算。
Part 05 → Part 07 的接口:Part 05 從 demo 走到 FastAPI server 那一刻,就要把 /ask response 預留 faithfulness_check / citation_check / observability 3 個欄位——就算那時候還沒實作 eval 邏輯,schema 先留好。Production launch 補 eval 模組時,response schema 不用改、API contract 不用 break。這是 Part 05「訊號 1(想量化 query 對錯)」接 Part 07 的具體接口(Part 05 訊號 1 = 「想量化 query 對錯」→ 走 Part 07;Part 05 訊號 3 = 「想給非工程師 demo」→ 走 Part 09,跟 Part 07 是不同路徑)。