故事:API 還活著,但它不回答了
某個下午,RAG API 的 health check 還在 200。但 /ask 開始集體 502。
沒有改 code。沒有動 docker-compose。沒有動 Nginx。沒有動 Qdrant 設定。
一小時前還好好的。
那天我盯著那個 502 看了很久。後來才搞清楚,這不是一個 bug,是環境層、容器層、網路層、整合層 4 個 stack 各自用一種非常合理的方式,決定在同一天交出問題。
Part 09 走完了文件端的 7 站——parsing、raw storage、Postgres metadata、ingestion queue、auth、document APIs、citation viewer。query 端在 Part 08 我把 4 個 capability 包成 5 種 query mode,routing 看起來已經很嚴格了。
但 deployment 端這條腿,「能跑」和「能上線」中間那段距離,比我想像中遠得多。
這篇走 10 個真實坑。它們在 4 個 stack 層上:
- 環境層(2 個)—— VM 規格、deploy key
- 容器層(3 個)—— env 沒進 container、Compose healthcheck 連帶擋 stack、build context 把整個倉庫搬進 Docker
- 網路層(3 個)—— Oracle Ingress、Nginx 反向代理、Cloudflare HTTPS trust chain
- 整合層(2 個)—— Qdrant payload index、production-style smoke test
每個坑都是真的。每個預防框架都是用時間跟錯誤換來的。
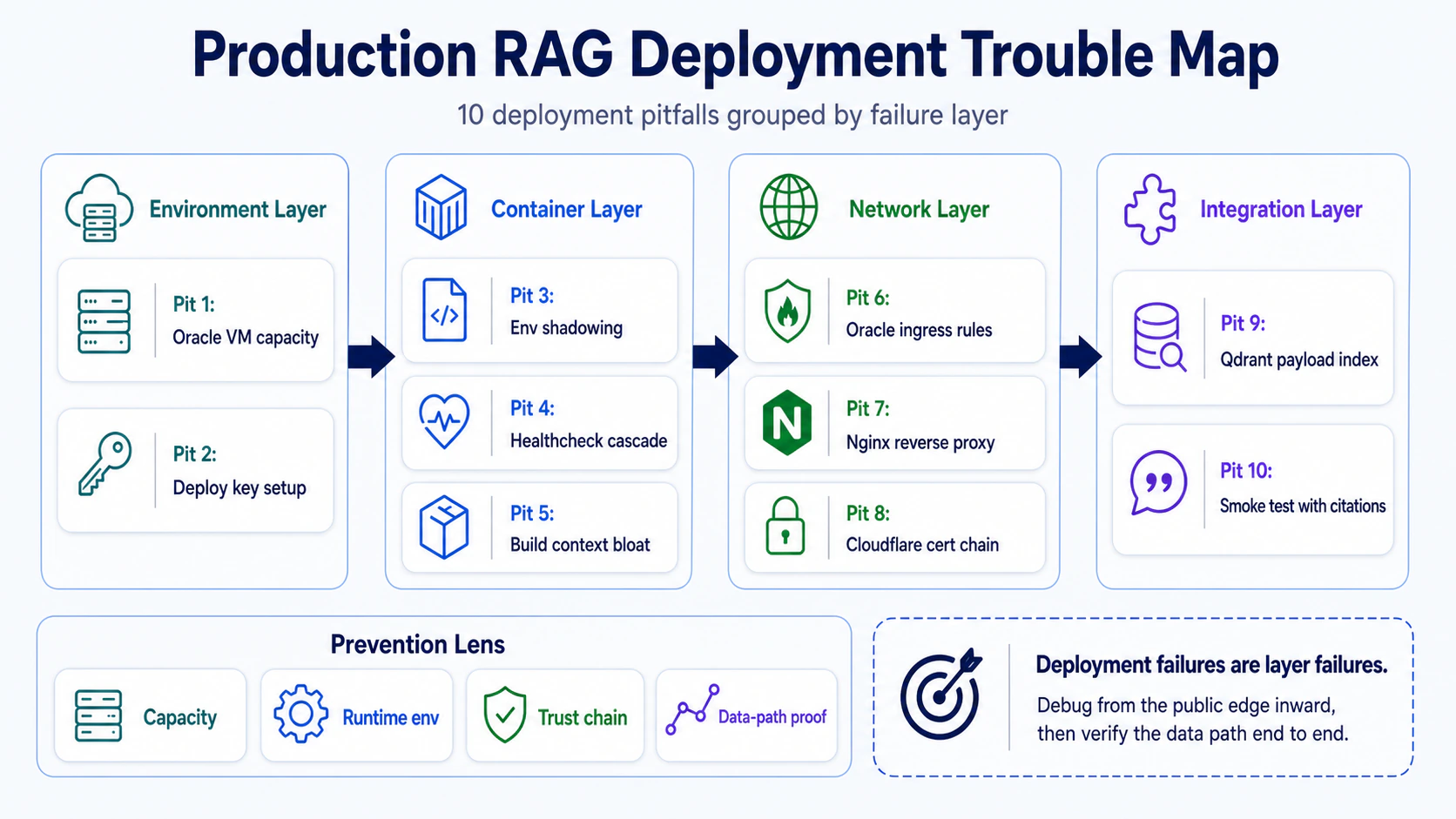
先把這 10 個坑畫成地圖,讀者會比較快看懂這篇不是在列流水帳。部署問題通常不是「API 壞了」這麼單純,而是某一層的邊界沒有被驗證:環境層拿不到穩定資源、容器層沒收到正確 runtime 設定、網路層 trust chain 斷掉、整合層沒有證明資料路徑真的通。
寫在前面:10 個坑裡有 2 個(坑 4、坑 5)來自真實部署清理,不是事後編出來的 checklist。重要的是操作教訓:Compose healthcheck 寫得不好,會把整個 stack 拖死。
版本提醒:部署指令比架構觀念老化得更快。本文的 Docker、Cloudflare、Qdrant Cloud、hosting 範例請視為 tested operational patterns;複製到 production 前,先查最新官方文件並在 staging 跑過。
第一層:環境層
坑 1:Oracle VM 搶不到 Always Free instance
Oracle Cloud 的 Always Free 給你最多 4 OCPU、24 GB RAM 的 ARM Ampere A1 形狀(你要自己配 1/2/3/4 OCPU + 對應 RAM,不是固定 4+24)。聽起來很多,部署一個小型 RAG API 絕對夠。
第一個現實是:你常搶不到。
熱門 region(us-ashburn-1、us-phoenix-1)回你的不是「建立失敗」,而是一行很安靜的錯誤:
{ "code": "InternalError", "message": "Out of host capacity." }你沒做錯任何事。這是 Oracle 對 Always Free 配額的資源排程——付費用戶在高需求 region 有優先權。
真實部署筆記:這個案例來自跨多個 Oracle region 等待、重試,最後才取得可用 Always Free 節點的過程。
可預防的思路:
- 預設 region 不是最優解——下單前先看那個 region 的當前負載,不要無腦接受預設值
- 評估非熱門 region(ap-seoul-1、ap-tokyo-1)對你實際使用者的延遲,別為了搶 instance 把自己網路搞慢
- 「搶新 instance」這個流程要先演練過一次——你需要的時候不會是冷靜的時候
個人選型(不是通用建議):對個人專案或小 prototype 來說,Oracle Always Free 的 spec 跟零成本是很合理的選擇。但如果你要 99.9% SLA,或你的團隊無法承受資源波動,這不是你該用的 VM。
坑 2:GitHub Private Repo + Deploy Key 配錯
從 localhost 到 VM 最常見的 auth 失敗:deploy key 格式錯、SSH config 缺一行、git clone 一直要密碼。
Deploy key 容易壞在哪:
- Deploy key 加到個人 SSH key 裡,不是 repo 的 Deploy keys 清單
- 格式選錯(ED25519 vs RSA,fingerprint 比對時容易對不起來)
.env不在 repo 裡,VM clone 下來的 repo 沒有.env——production env 沒跟著 code 走
真實部署筆記:這段整理的是 deploy key 設定錯誤;SSH 握手任何一步錯,VM 上的
git clone就會失敗。
可預防的思路:
- Deploy key 用
ed25519(key 長度比 RSA 短、簽章速度更快、密碼學界目前共識更推薦) .env永遠不要進 Git——做.env.example當模板,VM 的 env 走獨立通道(scp加密傳,或 Docker secret / env-file)- 第一次 clone 完,先驗
.env存在,再跑docker-compose up
第二層:容器層
坑 3:env 變數沒進 container(shadowing / build-time vs runtime)
Docker + FastAPI 最常見的單一部署失敗:API key 本機有效,production 403。
技術背景(已驗證):
ARG只在docker build期間可用;image 封包完、container 起來後就讀不到ENV在 build 跟 runtime 都活著docker-compose.yml的environment:是 runtime 注入,不是寫進 image.env自動內插在docker-compose up期間;但如果你用--env-file指定路徑,那個路徑是相對於執行目錄,不是 compose 檔案位置
真實部署筆記:這個模式來自一次 production debugging,同一晚同時遇到 port conflict 與 runtime env 沒送進 container。
可預防的思路:
任何 API key、secret、production 參數,必須同時滿足三件事:
- 存在
.env檔案裡 - 在
docker-compose.yml的environment:區塊宣告(或用env_file:) - 在 FastAPI 的
Settingsclass 裡有對應欄位(QDRANT_URL、SUPABASE_URL等)
第一次 deploy 完,在 VM 內跑:
docker exec <container> env | grep QDRANT確認那把 key 真的在裡面。
順帶:
python-dotenv的.env預設不讀export前綴。.env格式應該是KEY=***(不是export KEY=***`。
坑 4:Compose healthcheck 把整個 stack 拖死
這是整個系列裡最被低估的一個坑。
有一天 Qdrant 明明有 log 說自己起來了:
Qdrant HTTP listening on 6333但 docker-compose 整個 stack 沒起來,連帶 api 跟 worker 全部沒啟動。錯誤訊息長這樣:
Container llamaindex-demo-qdrant Error
dependency qdrant failed to start
dependency failed to start: container llamaindex-demo-qdrant is unhealthyQdrant 死了嗎?沒有。它活著。問題是 L34 寫的 healthcheck 用了 container 內部的 curl:
healthcheck:
test: ["CMD", "curl", "-fsS", "http://127.0.0.1:6333/healthz"]而 Qdrant 的 image 裡沒有 curl/wget。服務活著,健康檢查工具不存在,Compose 判定它死了,然後 depends_on: service_healthy 把所有下游服務一起擋住。
Docker 官方文件也確認:curl 在 minimal image(Alpine、scratch)預設不存在,需要改用 wget、裝 curl、或用 CMD-SHELL 加 cat / grep 來做 healthcheck。
真實部署筆記:這個案例來自一次 Compose 清理;服務本身活著,但 healthcheck 定義錯誤,讓 Compose 判定它 unhealthy。
可預防的思路:
- Healthcheck 不能依賴 container 內部有
curl跟wget——minimal image (Alpine busybox) 預設只有wget,scratch image 連wget都有可能被砍掉;最安全的是寫個 tiny Python / shell healthcheck script - 不要盲目用
depends_on: service_healthy——如果 health 定義本身有問題,會連帶擋住所有下游 - 把 healthcheck 跟服務本身解耦:服務起來 ≠ healthcheck 通過 ≠ 下游可以開始工作
我在 L34B 的修補包是這樣處理的:
services:
qdrant:
# 不再用 container 內部 curl
healthcheck:
test: ["CMD-SHELL", "ss -ltn | grep -q ':6333' || exit 1"]
interval: 30s
timeout: 5s
retries: 3
start_period: 30s
api:
depends_on:
qdrant:
condition: service_started # 改成 service_started,不要 service_healthy或者把 health 驗證搬到 host 端用 curl 跑 smoke test,container 內部完全不做 healthcheck。
坑 5:build context 4.31 GB——把整個倉庫搬進 Docker
另一個 L34 系列的真實紀錄:第一次跑 docker compose up --build,build log 印出這行:
transferring context: 4.31GB花了 335 秒。那是把整個倉庫連地基一起搬進 Docker。
Dockerfile 沒錯,image 也成功 build。但 .dockerignore 完全沒寫,於是:
.venv(Python 虛擬環境,幾 GB)整包進去storage/data資料夾(測試用 PDF、intermediate JSON)整包進去models(huggingface 快取)整包進去__pycache__整包進去.git整包進去
每一次 docker build 都在做一次無意義的全量搬運。
真實部署筆記:這個案例來自一次成功 build,但因為
.dockerignore不完整,花了數分鐘傳送不必要本機檔案的 Docker build。
可預防的思路:
# .dockerignore 最小可用版本
.venv
storage
data
models
__pycache__
.git
.env
*.log
*.pyc
.DS_Store.dockerignore 跟 .gitignore 一樣值得認真對待。第一個 commit 就該有。
第三層:網路層
坑 6:Oracle Ingress Rules——哪些 port 開、哪些不要開
Oracle Cloud 的 VCN(Virtual Cloud Network)有 Security List 層,這是 subnet 層級的 firewall(不是 instance 層級的——instance 層級的是 NSG / Network Security Group)。就算 VM 內部 UFW 配得對,Oracle Cloud Security List 沒開 port,外面流量就進不來。
把 Oracle VM 想成一棟建築:
Internet → Oracle Cloud 外牆(Security List)→ VM 自己的防火牆(UFW)→ Nginx → FastAPI containerIngress Rule 就是「哪些人、可以從哪個門進來」。
常見 port 的取捨:
- 22 (SSH):從 Mac 連 VM 用。Source CIDR 可以限定「你的 IP/32」(但如果你 IP 不固定,先用
0.0.0.0/0,免得鎖自己) - 80 (HTTP):外部
http://<public-ip>/health用,瀏覽器沒指定 port 時預設走 80 - 443 (HTTPS):綁了 domain 後,外部
https://api.yourdomain.com
不該開到公網的 port:
- 8000:VM 內部 MCP server 佔用,沒有對外需要
- 18000:FastAPI container 內部 port,VM 內 Nginx 連它就好,外部流量只該打到 80/443
- 6333 / 6334:Qdrant 的 REST / gRPC port。本專案用 Qdrant Cloud(不是自架 Qdrant),VM 這層根本不用開
真實部署筆記:這個案例來自「VM 內部 Nginx 有回應,但 public IP 沒回應」;根因是 Oracle Cloud Security List 沒允許 port 80。
可預防的思路:
- 在 Oracle Cloud Console:VCN → Security Lists → Add Ingress Rule,確認目的地 port 80 開了
- 分階段測試:先 VM 內
curl 127.0.0.1/health,再從 Maccurl http://<public-ip>/health - VM 內有反應但 public IP 沒反應,問題在 Oracle Security List,不在 Nginx
坑 7:Nginx 反向代理 + Cloudflare HTTPS trust chain
外部流量打到 VM,先經過 Nginx 反向代理才進 FastAPI container。Nginx 本身要配 HTTPS,但這裡有兩層 HTTPS 要分開處理:Cloudflare ↔ 外部使用者(Full strict)、Cloudflare ↔ Oracle VM(Origin Certificate)。
真實部署筆記:這個案例來自 Cloudflare Origin Certificate 設定錯誤:certificate / private key 不匹配,以及 SSL/TLS mode 沒切到 Full (strict)。
兩層 HTTPS 架構:
外部使用者 → HTTPS → Cloudflare(驗你的 domain 憑證)
Cloudflare → HTTPS → Oracle VM(驗 Cloudflare Origin Certificate)Cloudflare Origin Certificate 設定步驟:
- Cloudflare Dashboard → SSL/TLS → Origin Server → Create Certificate
- Hostname:
api.yourdomain.com(不要用 wildcard——縮小範圍) - 選 RSA 2048(相容 Nginx 預設)。這個 certificate 預設有效 15 年(不是 15 天),這是 Origin Cert 跟一般 LE cert 最大的差別
- 把產生的 PEM + KEY 檔用
scp傳到 VM 的/etc/ssl/cloudflare/ - Nginx config 指向這兩個檔
- Cloudflare SSL/TLS mode 設為 Full (strict)
不要做的事:
- 不要把 origin certificate 的 private key 用明文通道傳——
scp/sftp走 SSH 是加密的,傳 PEM 本身沒問題;但 email、即時通明文貼上、貼在 issue tracker 都不行 - SSL mode 不要設 Flexible——它會讓 Cloudflare → origin 這段走 HTTP,你等於把流量攤在 middlebox 前面
可預防的思路:
-
從外部跑
curl -v https://api.yourdomain.com/health,這驗的是使用者看到的路徑:Cloudflare edge certificate 是否對你的 domain 有效,不是在驗 VM 上的 Origin Certificate。 -
不要用
curl -v https://localhost/health驗 Cloudflare Origin Certificate。localhost不符合 certificate SAN,而且一般 OS trust store 不會信任 Cloudflare 私有的 Origin CA。 -
如果要直接驗 Cloudflare → origin 這一段,要用真實 hostname 當 SNI / Host header 連到 VM origin IP,並明確信任 Cloudflare Origin CA:
curl -v --resolve api.yourdomain.com:443:<origin-ip> \ --cacert cloudflare-origin-ca.pem \ https://api.yourdomain.com/health或用 OpenSSL 檢查 Nginx 實際送出的 certificate:
openssl s_client \ -connect <origin-ip>:443 \ -servername api.yourdomain.com \ -CAfile cloudflare-origin-ca.pem
核心心智模型:外部使用者驗到的是 Cloudflare edge certificate;Cloudflare 在 Full (strict) 模式下連回 VM 時,才會驗 Origin Certificate。
坑 8:Origin Certificate 跟私鑰對不起來
上一坑的子問題,但值得獨立成節——這是 HTTPS 設定最常見的單一失敗原因:
- Origin certificate 建立了、檔案傳了,但 Nginx config 指到錯的 PEM/KEY 檔
- 或者 Cloudflare SSL/TLS mode 沒改成 Full strict,於是流量卡在 Flexible 模式不上不下
真實部署筆記:「Cloudflare 已經是 Full (strict),但 origin HTTPS 還是連不上」的 troubleshooting,通常會收斂到兩件事:certificate/key 是否成對,以及 Nginx 是否指到正確檔案。
可預防的思路:
- 證書跟 key 統一放
/etc/ssl/cloudflare/——不要跟其他 cert 混在一起(Nginx 能放 cert 的地方太多,容易搞混) - VM 內驗證三件事:
sudo nginx -t # Nginx config 語法對不對 openssl x509 -in /etc/ssl/cloudflare/api.yourdomain.com.pem -text -noout # cert 不是空 openssl pkey -in /etc/ssl/cloudflare/api.yourdomain.com.key -check # key 格式對(不論 RSA / ED25519 都通用) - 設完用線上工具(ssllabs.com 的 SSL test)從外部驗一次憑證鏈
第四層:整合層
坑 9:Qdrant Cloud 連線 + payload index bootstrap
Qdrant Cloud 是託管服務——你不用自己維運 vector DB——但這不代表沒有坑。API key 傳輸、runtime env 設定、Qdrant Cloud collection 狀態,都需要主動驗證。
常見 Qdrant Cloud 問題:
- API key 傳壞:Qdrant Cloud API key 是
eyJ...開頭的 JWT 格式;.env多了空白或尾端換行,Python client 會當成 malformed 跳過 - Collection 不存在:第一次 deploy 完,Qdrant Cloud collection 是空的;
/ask不是回 500,而是 graceful 回index_ready: false - Runtime env 被蓋掉:如果 VM 上另一個服務也用
QDRANT_API_KEY當 env 名,docker-compose env 會被覆蓋
真實部署筆記:這段整理的是 Qdrant Cloud 連線失敗:API key 格式、runtime env injection、第一次部署時 collection 狀態都要確認。
Payload index 不只是效能問題,是 ACL 問題。
Qdrant Cloud 的 payload index 不只是讓搜尋變快——它也支撐 ACL filter。每個 chunk 的 payload 帶 tenant_id + document_id;query 時 filter 這兩個欄位,確保 user A 看不到 user B 的文件。
如果 payload index 沒 bootstrap,filter 失效——這就是 Part 09 提到的「Q3 contract 出現別家公司內容」的其中一個根因。
Qdrant 官方文件確認:payload index 是一個 secondary data structure,vector search 帶 filter 時會查它;沒建 index,filter 會退化或失敗。
create_payload_index必須對 tenant_id、document_id 這些高基數欄位做。
可預防的思路:
- 驗證
.env裡的 API key 格式乾淨(`QDRANT_API_KEY=***、尾端沒空行) - 第一次 deploy 完,在 VM 內測:
docker exec <container> python -c "from qdrant_client import QdrantClient; c = QdrantClient(url='https://xxx.qdrant.tech', api_key=*** print(c.get_collections())" - 確認 collection 存在 + payload index 有 bootstrap。如果沒有,在 Qdrant Cloud Dashboard 手動觸發,或跑對應的 init script。
坑 10:Ingestion smoke test——只驗 /health 不夠
部署完最重要的事不是「API 還活著」,是「RAG 資料路徑還活著」。沒有 smoke test 的部署 = 沒驗證過的部署。
Smoke test 必須確認的不只是 /health:
/health→ 200 OK(Nginx、container、FastAPI 都活)/query-profiles→ 拿到 profiles(API endpoint 有工作)- POST 一個測試 query 到
/ask→ 拿到答案(Qdrant Cloud 有資料、payload index bootstrap 過) - Citation 存在(
citations陣列非空)
真實部署筆記:這個 smoke test 形狀來自部署後不只驗 HTTP service,也驗 Qdrant collection、payload index 與 citation path。
可預防的思路:
把 smoke test 寫成腳本,當 deploy pipeline 的最後一步:
BASE_URL="https://api.yourdomain.com"
TOKEN=$(python get_access_token.py)
echo "1. health check"
curl -s "$BASE_URL/health" | jq '.status == "ok"' || exit 1
echo "2. query-profiles check"
curl -s "$BASE_URL/query-profiles" | jq '.supported_modes' || exit 1
echo "3. smoke document ingestion"
# ... ingest 一份已知的 smoke 文件 ...
echo "4. smoke query with citation"
curl -s -X POST "$BASE_URL/ask" \
-H "Authorization: Bearer $TOKEN" \
-d '{"question": "smoke 文件的獨特 marker 是什麼?", "query_mode": "safe"}' \
| jq '.citations | length > 0' || exit 1Smoke test 不是「有拿到答案就好」——它必須確認 citation 存在。有答案不等於 RAG 資料路徑完整。
補一層:Agentic / tool workflow 上線後,最先壞的是 timeout
上面 10 個坑是把 RAG API 推上線會遇到的基礎設施問題。但如果你的 RAG 已經像 Part 08 那樣有 agentic mode、像 Part 09 那樣有 ingestion queue、像 Part 07 那樣有 offline eval,deployment 還會多一個問題:哪些事情可以留在 /ask,哪些事情一定要移到 worker?
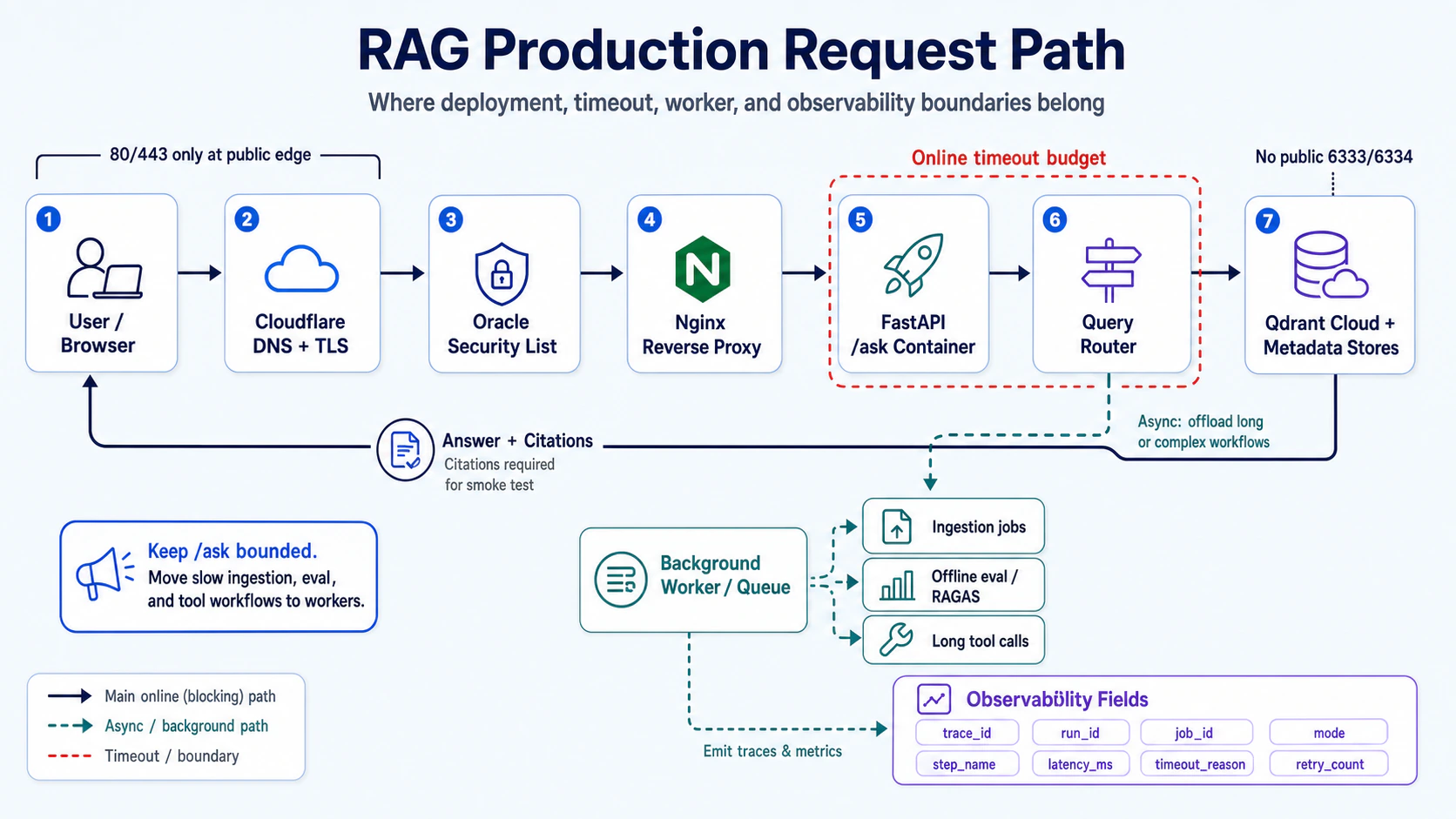
我的經驗是:線上 /ask 只應該承擔「有明確 timeout budget 的 blocking path」。只要工作具備下面任一特徵,就不要讓它卡在同一個 HTTP request 裡:
- 會跑 ingestion、chunking、embedding、payload index bootstrap
- 會做 RAGAS / offline eval / regression suite
- 會呼叫不穩定或不可預期延遲的外部 tool
- 需要 retry、人工審核、或可能跑超過 10 秒
- 失敗後不能只回 502,而要保留 job 狀態與可重跑線索
我會把 production path 分成兩條:
| 路徑 | 放什麼 | 成功條件 |
|---|---|---|
Online /ask path | auth、routing、retrieval、rerank、generation、citation assembly | bounded latency、可觀測 trace、失敗時回可解釋錯誤 |
| Background worker path | ingestion、offline eval、long tool call、index bootstrap、批次 regression | 有 job_id、可 retry、可查狀態、可回補結果 |
這裡最重要的不是用了哪個 queue,而是你有沒有把 timeout、retry、trace 這三件事從一開始就當成產品邏輯。最少我會在每個 request/job 記這些欄位:trace_id、run_id、job_id、mode、step_name、tenant_id、latency_ms、timeout_reason、retry_count、cost_usd。
Part 07 的 per-step trace、Part 08 的 query mode、Part 09 的 ingestion queue,到了部署層其實會合成同一個要求:不要只問服務有沒有活,要問每一段工作有沒有被限制、被記錄、被驗證。
這些是我的選擇,不是通用建議
這 4 條不是「怎麼做」的教學,是「我為什麼這樣選」的交代。如果你跟我條件不同(預算、團隊規模、資料合規、預期流量),結論可能完全相反。
Oracle VM(不選 AWS / GCP / Azure) 我選 Oracle Cloud Always Free 不是因為它最穩,而是它免費、spec 對小型 RAG API 足夠。代價是熱門 region 不穩定、沒有 SLA、文件複雜。如果你要 99.9% uptime 或你的團隊需要更好的 migration path,這不是首選。
Qdrant Cloud(不選自架 Qdrant / Pinecone / Weaviate) 我選 Qdrant Cloud 因為我不想自己維運 vector DB(備份、升級、監控都要成本)。代價是你的資料在第三方那邊、網路延遲比 local 高、費用隨用量成長。如果你的資料隱私要求極嚴,或向量搜尋量巨大,自架可能更合適。
Cloudflare(不直連 VM IP、不用 Certbot / Let’s Encrypt) 我選 Cloudflare 是因為我本來就在用它管我的 domain,而且 Origin Certificate 設起來比 Certbot 簡單(不用處理 DNS challenge、不用煩憑證更新)。代價是你把整個 DNS 生命週期綁在 Cloudflare 上——如果 Cloudflare 出事,你的 API 跟著倒。
Docker Compose + L34 patch(不是 k8s) 這個專案體量用 k8s 是過度工程。Compose + 一台 VM 對單一 RAG API 來說是 sweet spot。代價是水平擴展要手動做,但這個專案還沒到那個量。