故事:Q3 合約查到了,內容是別家公司的
某天下午,業務部門在 demo 環境測自家 RAG。業務輸入「我們跟供應商的 Q3 合約,終止條款是什麼」——RAG 回了一段條文,引用編號 [1] 對應到一份文件,業務打開看:合約編號是 NatyNites-Q3-2024,不是自家的。
demo 環境。沒有 user 區隔。整套 RAG 跑得起來、答案看起來合理、citation 也有、但撈到的是別人的資料。這個 bug 在 demo 階段根本不會被發現——demo 環境只有自己一家的文件。
但 production 環境就藏不住。user A、user B、user C 同時在用,Qdrant 裡的 chunk 不分誰家的;同一天某 user 投訴「答案看起來是別家公司的」、查 log 才看到三家公司(nattynites、company-a、company-b)的 user 都打中同一批 chunk。重標所有 chunk 的 tenant_id、跑一次 ingestion、整個流程 debug 了三天才把污染的 chunks 隔乾淨。這個 bug 不是 RAG 寫錯、是文件端的 metadata 設計從來沒被當成 production 級問題看待——demo 環境永遠只有自家資料,沒人會主動設計 cross-tenant 測試案例。
Part 08 把 faithfulness / citation / tracing / cost 4 個 capability 跟 5 種 query mode 設計得再好,query 端 routing 解不掉文件端沒設計的問題。這一篇 Part 09 拆文件進系統後實際走過的 7 個環節、為什麼「Vector DB 不能當 source of truth」、ACL 在 production 為什麼不是一層 filter 就夠。
Tested API shape 提醒:本文程式片段示範的是這個專案採用的實作形狀,不是永久不變的 SDK contract。請 pin Python 套件版本,替每段關鍵 snippet 保留最小 smoke test,升級 LlamaIndex / Qdrant / FastAPI / eval framework 前先對照官方文件。
文件端的 7 站旅程(高層)
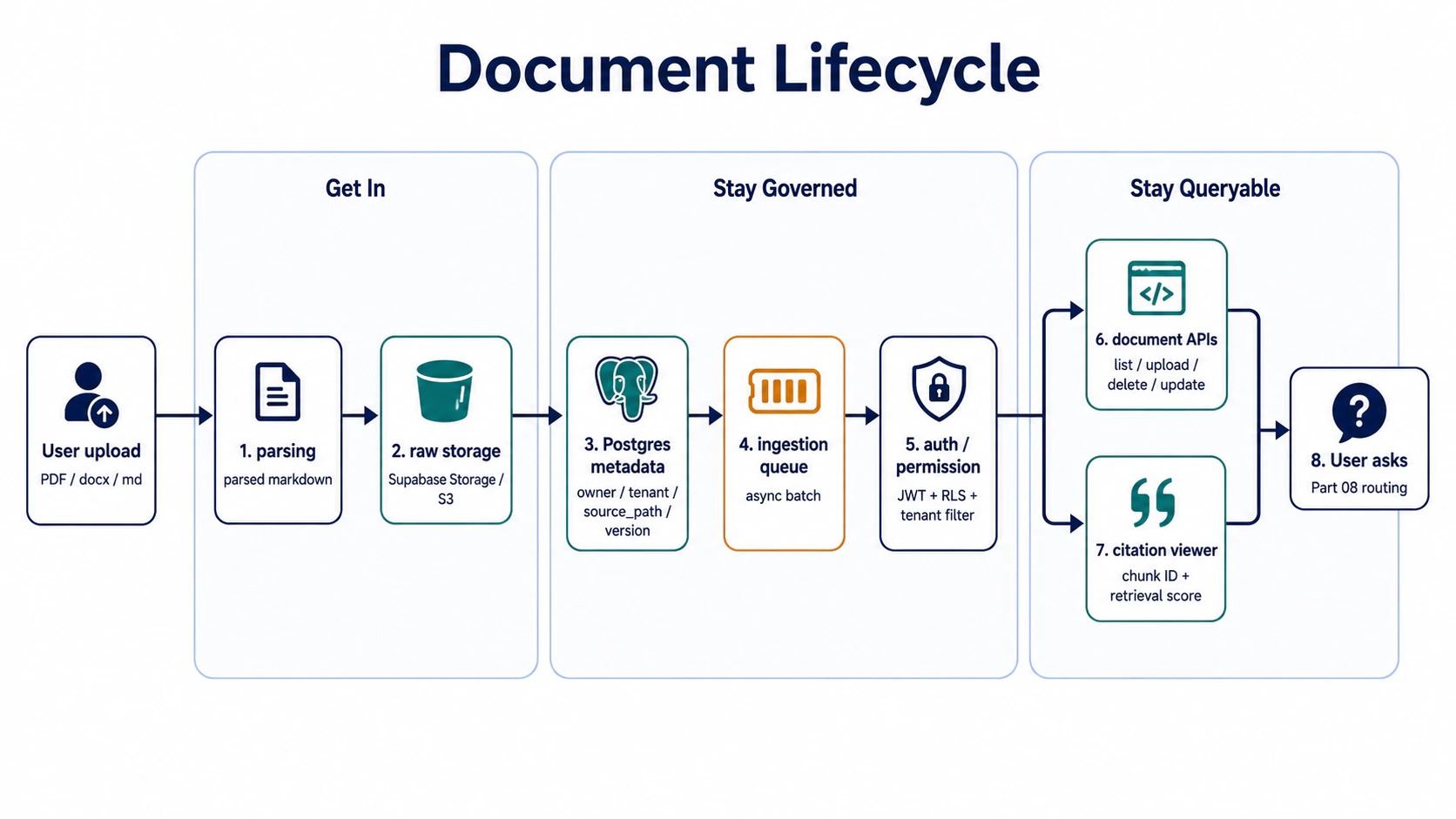
7 站分成 3 條主線:
- 進得來(站 1-2):檔案怎麼從硬碟變成可索引的東西
- 管得住(站 3-5):metadata 怎麼存、誰能看、怎麼不漏
- 查得到(站 6-7):管理後台、答案可解釋性
先講結論:7 站可以拆開各自實作,但 metadata 設計(站 3)跟 ACL(站 5)是兩個常被低估、爆掉就要重做的環節。剩下 5 站相對線性、實作後不太會再回頭大改。
第一條主線:進得來(parsing + raw storage)
第 1 站:parsing——把 PDF / docx 變成 parsed markdown
檔案丟進系統那一刻,第一件事是 parsing。PDF 跟 docx 是給人看的格式,不是給 embedding model 看的——PDF 抽出來的是座標流、docx 是 XML 結構,chunking 跟 embedding 直接吃這些原始格式效果都很差。
中間要有一層 parsed markdown:把 PDF / docx 轉成結構化的 markdown(標題、列表、表格、code block 都保留)。
Takeaway:parsed markdown 是好的中間格式——保結構(標題層級、表格、code block)、好切塊(按 heading / paragraph 切都有意義)、可重處理(改 chunking 策略不用重 parse)。
反例(必看):存 PDF 二進位進 object storage,parsing 在 query 時才做。
❌ PDF 進 object storage → query 時才 parse → chunking
✅ PDF 進 object storage → parse 一次成 markdown → 存 markdownquery 時才 parse 聽起來省空間,實際上每次 query 都要重做一次 parsing、latency 飆高;改 chunking 策略要重 parse 所有文件(幾萬份 PDF 等到天荒地老)。parsing 是一次性工作、結果要 reuse。
反例情境:早期試過 query 時 lazy parse,發現每次 query 慢 800ms、改 chunking 一次跑了 6 小時,後來決定 ingestion 階段一次性 parse 完。
補一個定位:Multimodal / Document RAG 不是「多模態聊天」
這裡要補一個 2026 之後做文件型 RAG 很容易混淆的名詞:Multimodal / Document RAG。
它不是「讓 chatbot 可以看圖片」這麼簡單。放在 Part 09 的語境裡,它指的是:文件進系統時,不只把文字抽出來,還要保留 table、image、layout 這些會影響答案與 citation 的結構訊號。
如果只把 PDF parse 成一大段文字,很多企業文件會壞在這裡:
| 內容類型 | ingestion 時要保留什麼 | retrieval / citation 會用到什麼 |
|---|---|---|
| text | paragraph、heading、section path | 一般 chunk retrieval、parent expansion |
| table | table JSON、markdown table、row / column header | 金額、條款比較、規格表查詢 |
| image | image caption、figure pointer、alt text、OCR text | 圖表、流程圖、截圖型文件 |
| layout | page、bbox、reading order、OCR confidence | citation viewer 高亮、審計、低信心重處理 |
我會把 parsed markdown 當成主幹,但旁邊一定要保留一份 element-level metadata。概念上像這樣:
{
"document_id": "doc_123",
"elements": [
{
"type": "table",
"section_path": ["MSA", "Termination"],
"page": 12,
"bbox": [88, 140, 512, 430],
"ocr_confidence": 0.97,
"table_markdown": "| Term | Notice | Fee | ... |",
"table_json": {
"columns": ["Term", "Notice", "Fee"],
"rows": [["Early termination", "30 days", "2 months"]]
}
},
{
"type": "image",
"section_path": ["Architecture", "Network"],
"page": 18,
"bbox": [72, 96, 540, 620],
"image_caption": "Cloudflare -> FastAPI -> Qdrant request path",
"figure_pointer": "s3://bucket/doc_123/page_18_fig_02.png"
}
]
}這些欄位不是為了資料庫看起來很完整,而是為了後面三件事:
- retrieval 可以選對 representation:文字走 text chunk,表格查 table row,圖表走 caption / OCR / figure pointer。
- citation viewer 可以真的定位:不是只顯示「第 12 頁」,而是能 highlight 到 bbox 或 section path。
- eval 能判斷 parser 失敗:如果 OCR confidence 低、table header 消失,這是 ingestion failure,不是 LLM failure。
Takeaway:Document RAG 的第一個分水嶺不是 model 有多強,而是 ingestion 有沒有保住文件結構。text / table / image / layout 如果在 parsing 階段被壓成同一段 plain text,後面再強的 retrieval 都只能猜。
第 2 站:raw storage——物件儲存 + Postgres 分工
Parsed markdown 跟原始 PDF 都要存。但不要全部塞 Postgres。
物件儲存(Supabase Storage / S3 / GCS)跟 RDB 分工:
| 資料 | 放哪 | 為什麼 |
|---|---|---|
| 原始 PDF / docx | Object storage | 不常讀、檔案大、cost 敏感 |
| Parsed markdown | Object storage | chunking 改要重讀、不進 DB |
| 結構化 metadata | Postgres | 要查詢、要 join、要 ACL |
| Embedding | Vector DB | 專門給 similarity search |
Takeaway:Postgres 存 metadata、不存 content。Object storage 存 content、不存 metadata。Vector DB 是 metadata 的衍生,不是 source of truth(這條進到第 3 站會展開)。
反例(必看):把 markdown 直接塞 Postgres BYTEA 欄位、metadata 用 JSONB 一起塞。
-- ❌ 反例
CREATE TABLE documents (
id UUID PRIMARY KEY,
raw_content BYTEA, -- markdown 塞這
metadata JSONB, -- tenant_id, owner, version 一起塞
embedding vector(1536)
);為什麼錯:metadata 要 query / index / filter(撈某 user 的所有文件、清 ACL),JSONB 查起來慢、index 麻煩;markdown 要重讀(改 chunking 策略要撈全部),用 BYTEA 傳輸整份文字比從 object storage 撈貴。結構化跟非結構化要分開。
第二條主線:管得住(metadata + ingestion + auth)
第 3 站:Postgres metadata = source of truth(核心論點)
這是 Part 09 最容易被忽略、爆掉成本最高的論點。
Vector DB(Qdrant / Pinecone / Weaviate)設計的目的是 similarity search,不是 source of truth。所以 metadata 一定要先在 Postgres 落地、Vector DB 是 Postgres 派生出來的檢索引擎。
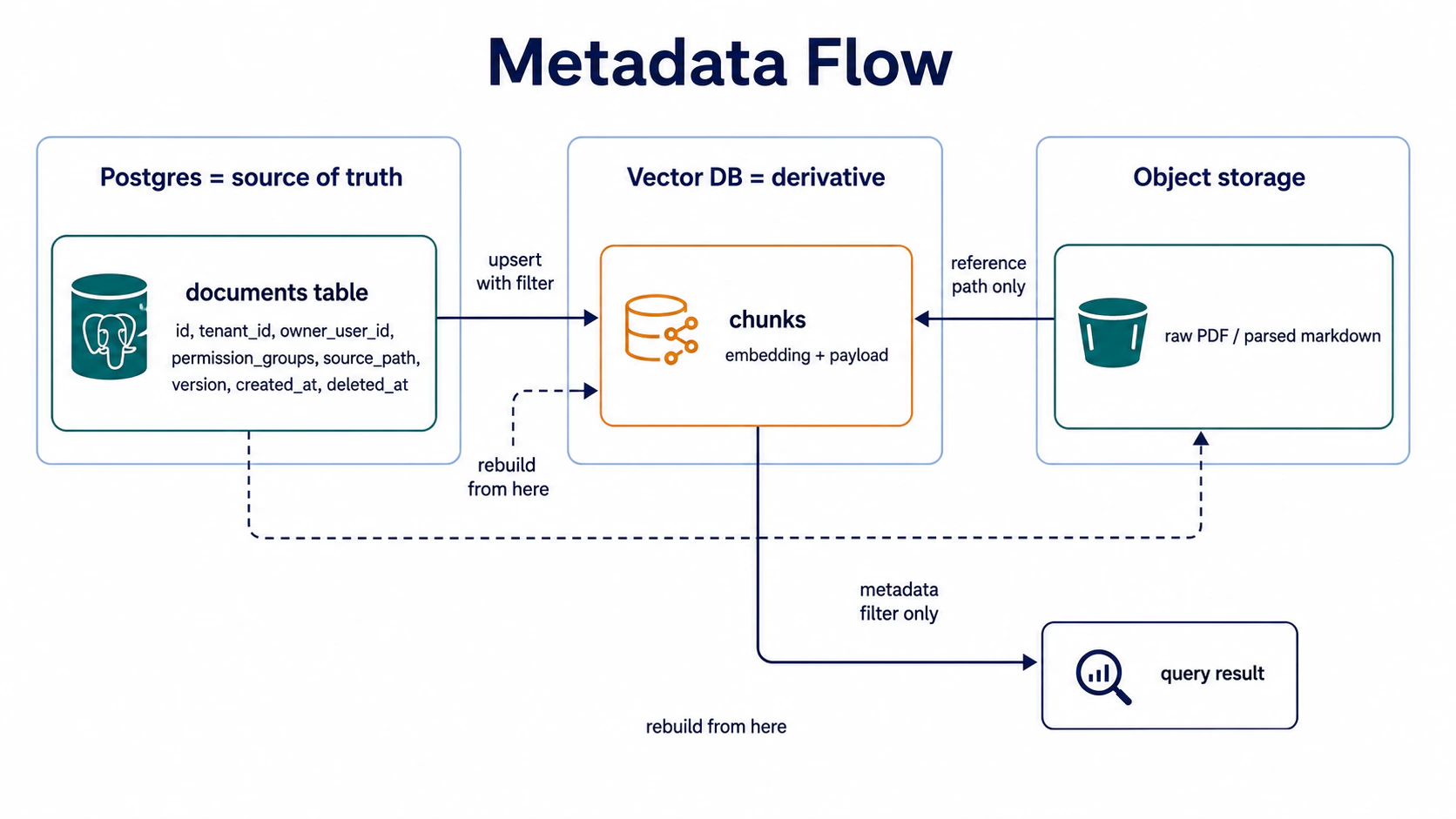
metadata 拆成幾類:
CREATE TABLE documents (
id UUID PRIMARY KEY,
-- 身份類
tenant_id TEXT NOT NULL, -- 哪個公司 / workspace
owner_user_id TEXT NOT NULL, -- 誰上傳
permission_groups TEXT[], -- 在這個 tenant 裡有什麼角色
-- 來源類
source_path TEXT NOT NULL, -- "contract" / "faq" / "runbook" / "open"
-- 版本類
version INT DEFAULT 1,
parent_document_id UUID, -- 同一份文件多次上傳的 lineage
created_at TIMESTAMPTZ DEFAULT now(),
deleted_at TIMESTAMPTZ, -- soft delete 不直接砍
-- ingestion 狀態
ingestion_status TEXT, -- pending / processing / done / failed
ingestion_job_id TEXT -- 對到 ingestion queue
);Takeaway:Postgres 是 source of truth、Vector DB 是 metadata 衍生、Object storage 是 content 載體。刪文件時,先 Postgres 標
deleted_at、再刪 Vector DB chunks、再刪 Object storage 內容——順序反了就會出孤兒。
反例(必看):把 tenant_id / owner_user_id 塞 Vector DB 的 payload、Postgres 只存文件名。
# ❌ 反例
qdrant.upsert(
points=[
PointStruct(
id=chunk_id,
vector=embedding,
payload={
"file_name": "Q3-contract.pdf",
"tenant_id": "company-a", # metadata 塞 vector DB
}
)
]
)為什麼錯:刪文件的時候,Postgres 沒有 tenant_id → 不知道 Vector DB 裡哪些 chunk 要刪;ACL 查詢(user A 能不能看這份文件)要去 Vector DB payload filter 撈,比 Postgres indexed column 慢 10 倍;Qdrant 倒資料重建時,metadata 全部要重塞。把 metadata 放錯地方就是要重做的徵兆。
反例情境:早期試過 metadata 全塞 Qdrant payload、Postgres 只存檔名,結果刪一份文件要先去 Postgres 查 file_name、再去 Qdrant 找所有 payload 包含這檔名的 chunk、再一個一個刪。Qdrant 沒辦法用 file_name filter(payload 沒 index)、只能 full scan。一萬份文件刪一次跑了 40 分鐘。後來決定 Postgres 是 source of truth、Vector DB 是衍生、刪文件用 Postgres
id直接 query Qdrant 拿 chunk_ids 批次刪。
第 4 站:ingestion queue——同步 ingestion 撐不住 production
Incoming file 進到系統後,要走 parsing → store → metadata → index 這條 pipeline。這條 pipeline 不該在 API request 同步觸發。
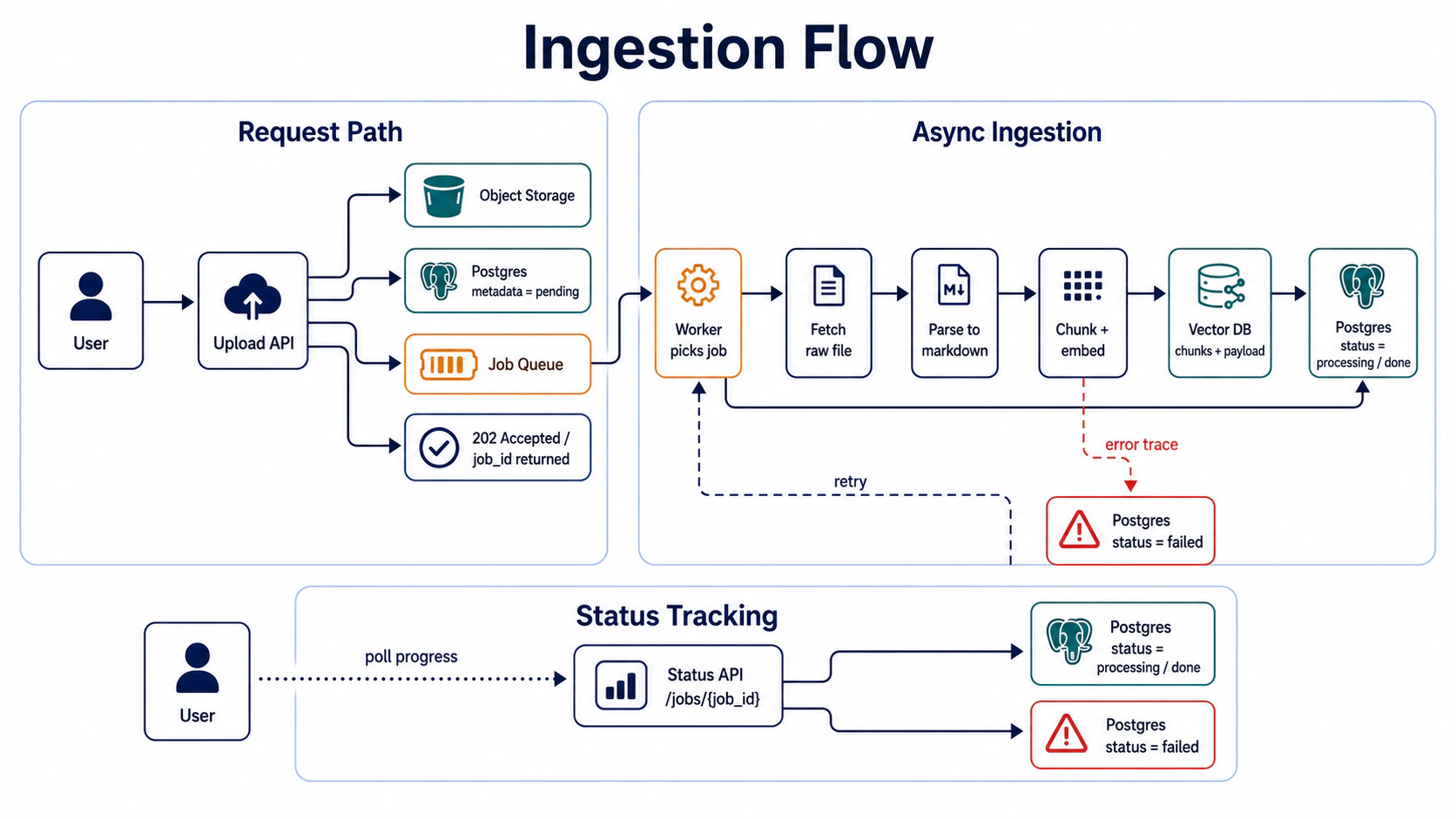
Takeaway:upload API 只負責收檔 + enqueue job、不負責跑 ingestion。Worker 異步跑、status 寫回 Postgres、user 透過
job_id查進度。
反例(必看):API request 同步觸發整條 ingestion(parse + chunk + embed + upsert)。
# ❌ 反例
@app.post("/upload")
async def upload(file: UploadFile):
markdown = await parse(file) # 5 秒
chunks = await chunk(markdown) # 2 秒
embeddings = await embed(chunks) # 10 秒(外部 API)
await upsert_to_vector_db(embeddings) # 3 秒
return {"status": "done"} # 總共 20 秒為什麼錯:20 秒同步 → user 端 timeout、上傳失敗但檔案其實已寫入 storage 變孤兒、worker crash 後沒重試。Production ingestion 一定要 async、要有 retry、要有 status trace。
反例情境:上線初期用同步 ingestion,某天 500 個 user 同時上傳 → API 全部 timeout、檔案卡在 storage 沒進 DB、user 抱怨「檔案傳了但查不到」。改 job queue 之後,202 Accepted +
job_idpoll 進度、retry 機制、status trace 三件補齊;後續半年處理了 12 萬份文件、p99 ingestion latency 控制在 8 分鐘(500 份並行 worker)。同步 ingestion 撐不住 production 不是「會慢」、是「會壞」——timeout、孤兒檔案、user 抱怨三個一起來。
第 5 站:auth + permission——ACL 多層防護(4 個失敗情境)
Part 08 的 query 端 routing 決定這題走哪個 mode,document 端的 ACL 決定這 user 能撈到哪些文件。兩端各自獨立、合在一起才是完整的存取控制。
ACL 設計在 production 容易死的地方有 4 個,按「破的時間點」由早到晚排:header spoofing → 無 tenant filter → app-layer filter 沒 RLS → JWT 沒 membership check。每一個都會讓 cross-tenant 資料 leak、只是觸發點不同。下面 4 段各自拆。
三個術語先講清楚:user_id / tenant_id / permission_groups
進 4 個失敗情境前,先講三個常被混用的欄位:
user_id = 這個人是誰(身份,來自 JWT sub claim)
tenant_id = 這個人正在操作哪個組織 / workspace(公司、團隊、project)
permission_groups = 這個人在這個 tenant 裡有什麼角色(admin / staff / viewer / finance 等)一個 user 可以屬於多個 tenant;一個 tenant 裡可以有不同 permission_groups。例如 Daniel 在 nattynites tenant 裡是 hotel_admin:
{
"user_id": "daniel",
"tenant_id": "nattynites",
"permission_groups": ["default", "hotel_admin"]
}ACL 4 層防護的核心問題都是圍繞這三個欄位:誰能拿 user_id(身份驗證)、能不能進 tenant(授權)、在 tenant 裡能做什麼(角色)。下面 4 個失敗情境就是這三個問題的不同死法。
失敗 1:Header spoofing(開發版 ACL 死法)
# ❌ 反例:開發階段用 header 模擬身份
curl -X POST https://api.example.com/ask \
-H "X-User-Id: alice" \
-H "X-Tenant-Id: company-a" \
-d '{"query": "Q3 合約"}'# ❌ 反例:FastAPI 直接 trust header
@app.post("/ask")
async def ask(req: Request, body: AskRequest):
user_id = req.headers.get("X-User-Id") # 任何人都能改
tenant_id = req.headers.get("X-Tenant-Id") # 任何人都能改
return await rag.ask(body.query, user_id, tenant_id)為什麼錯:header 是 client 控制的、攻擊者改 X-User-Id: ceo 就假冒 CEO。開發階段用 header 模擬身份是合理的,正式 production 一定要用真實的 token 驗證(Supabase Auth JWT、Auth0、Clerk 等),user_id 從 token 解析、不從 header 讀。
修法:把 header mode 換成 JWT mode。
# ✅ Production:Authorization Bearer token
curl -X POST https://api.example.com/ask \
-H "Authorization: Bearer eyJhbGciOiJIUzI1NiIs..." \
-d '{"query": "Q3 合約"}'# ✅ user_id 從 JWT sub 解析、不從 header
@app.post("/ask")
async def ask(req: Request, body: AskBody, auth: AuthContext = Depends(verify_jwt)):
user_id = auth.user_id # 來自 token.sub、無法偽造
tenant_id = auth.tenant_id # 來自 membership table
return await rag.ask(body.query, user_id, tenant_id)失敗 2:無 tenant filter(retriever 撈全庫)
JWT 驗完身份後,retriever 撈 chunks 時必須加 tenant filter,不然還是會 leak。
# ❌ 反例:Qdrant query 沒加 tenant filter
def retrieve(query: str, user_id: str, tenant_id: str):
embedding = embed(query)
results = qdrant.search(embedding, top_k=10) # 沒 filter、撈全庫
return resultsUser A 在 company-a tenant 問「Q3 合約終止條款」
→ Qdrant 搜全庫、撈到 10 個最相近的 chunk
→ 其中 2 個是 company-b 的合約
→ LLM 把 company-b 的條文回給 User A修法:每次 Qdrant query 都帶 tenant filter。Qdrant Python client 用 models.Filter + models.FieldCondition + models.MatchValue 組 query_filter:
Qdrant API 漂移提醒:舊範例常見
client.search(...),新版 Qdrant Python client 範例可能改用query_points(...),request object 也可能略有差異。真正不能變的是 invariant:每次 retrieval call 都必須帶 tenant filter;method name / request wrapper 請依你 pin 的 Qdrant client 版本調整。
# ✅ 強制 tenant filter(Qdrant 1.x python client)
from qdrant_client.http import models
def retrieve(query: str, user_id: str, tenant_id: str):
embedding = embed(query)
results = qdrant.search(
embedding,
top_k=10,
query_filter=models.Filter(
must=[
models.FieldCondition(
key="tenant_id",
match=models.MatchValue(value=tenant_id), # 強制 filter
),
]
),
)
return results但光是 app-layer filter 不夠(見失敗 3)。
失敗 3:App-layer filter 沒有 Postgres RLS(程式碼一 bug 就破)
# ❌ 反例:只有 app 層強制 filter
@app.get("/documents")
async def list_documents(req: Request):
user_id = req.headers.get("X-User-Id")
tenant_id = req.headers.get("X-Tenant-Id")
# 漏寫 tenant_id filter ← 這個 bug 一次、就全庫 leak
return await db.query("SELECT * FROM documents")為什麼錯:app 層 filter 依賴工程師每次都記得寫、少寫一個就全庫 leak;多一層 Postgres RLS(Row Level Security)作 defense in depth 是對的,但 tenant context 不能從 client-controlled header 直接拿,也不能用字串拼接 SET。tenant 必須來自已驗證的 JWT + membership,而且要綁在單一 transaction 裡,避免 connection pool 把上一個 request 的 tenant 狀態漏到下一個 request。
-- ✅ Postgres RLS:DB 層強制 filter
ALTER TABLE documents ENABLE ROW LEVEL SECURITY;
ALTER TABLE documents FORCE ROW LEVEL SECURITY;
CREATE POLICY tenant_isolation ON documents
USING (
tenant_id = current_setting('app.tenant_id', true)
AND EXISTS (
SELECT 1
FROM tenant_memberships tm
WHERE tm.user_id = current_setting('app.user_id', true)
AND tm.tenant_id = documents.tenant_id
)
);# ✅ tenant context 來自 JWT + membership,並且只在 transaction 內有效
@app.get("/documents")
async def list_documents(
req: Request,
auth: AuthContext = Depends(verify_jwt),
):
requested_tenant = req.query_params.get("tenant_id")
membership = await db.fetchrow(
"""
SELECT tenant_id
FROM tenant_memberships
WHERE user_id = $1 AND tenant_id = $2
""",
auth.user_id,
requested_tenant,
)
if not membership:
raise HTTPException(403, "No tenant access")
async with db.transaction():
# set_config(..., true) 是 transaction-local。
# 這樣可以避免 SQL injection,也避免 pooled connection 洩漏上一個 tenant。
await db.execute("SELECT set_config('app.user_id', $1::text, true)", auth.user_id)
await db.execute("SELECT set_config('app.tenant_id', $1::text, true)", membership["tenant_id"])
# 就算這裡忘了加 WHERE tenant_id = ...,RLS 還是會擋
return await db.fetch("SELECT * FROM documents")兩個 production 細節要特別記:
- 一般 API 流量要用受限 app role。table owner 和帶
BYPASSRLS的 role 可能繞過 policy;FORCE ROW LEVEL SECURITY可以讓 table owner 也套 policy,但 superuser /BYPASSRLSrole 仍然不該進 request path。 - 加 cross-tenant integration test:user A 在
company-a只能列出company-a文件;同一個 JWT 改查tenant_id=company-b必須回 403;request 結束後重用同一條 pooled connection,在沒有重新設定 transaction-local context 前不能看到任何 tenant 資料。
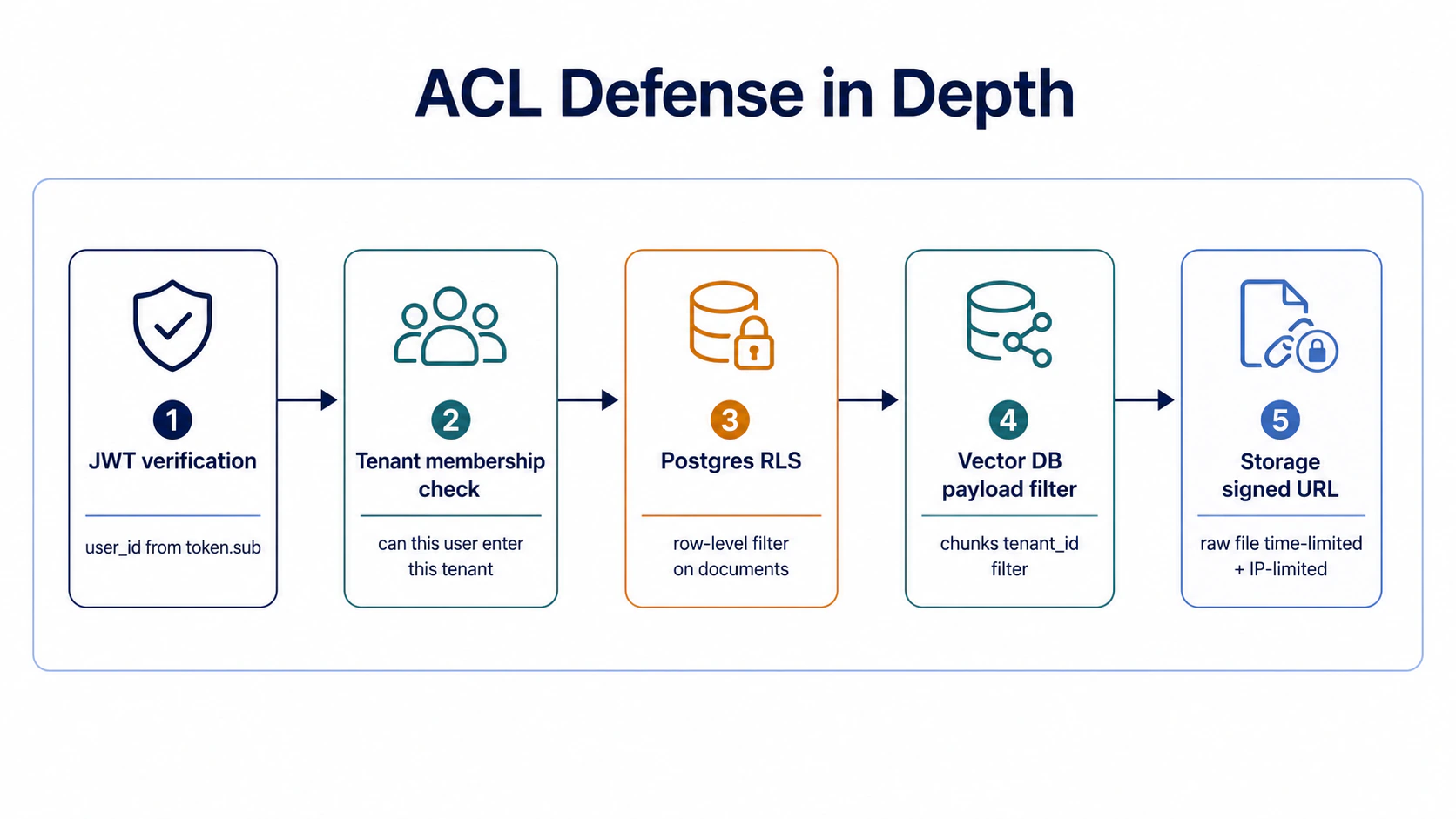
Takeaway:ACL 不是一層就夠。Postgres RLS + Vector DB payload filter + Storage signed URL + App-layer filter四層各自擋不同情境。任何一層單獨 fail、其他三層還能擋住——這是 defense in depth 的真實意義。
失敗 4:JWT 沒 membership check(拿到 token 不等於能進 tenant)
# ❌ 反例:JWT 驗完就信
@app.post("/ask")
async def ask(req: Request, body: AskBody, auth: AuthContext = Depends(verify_jwt)):
tenant_id = req.headers.get("X-Tenant-Id") # 從 header 拿 tenant
return await rag.ask(body.query, auth.user_id, tenant_id)為什麼錯:JWT 只能證明「這個人是誰」(sub: alice),不能證明「alice 能不能進 company-b tenant」。攻擊者拿到合法 token 後改 header 把 tenant 換成別家,照樣撈到別家資料。
修法:JWT 證身份、membership table 證授權、tenant 從 membership 撈不從 header 拿。
-- ✅ Membership table
CREATE TABLE tenant_memberships (
user_id TEXT NOT NULL,
tenant_id TEXT NOT NULL,
permission_groups TEXT[],
PRIMARY KEY (user_id, tenant_id)
);# ✅ tenant 從 membership 撈
@app.post("/ask")
async def ask(req: Request, body: AskBody, auth: AuthContext = Depends(verify_jwt)):
membership = await db.query(
"SELECT tenant_id, permission_groups FROM tenant_memberships WHERE user_id = $1",
auth.user_id,
)
if not membership:
raise HTTPException(403, "No tenant access")
tenant_id = membership["tenant_id"] # 從 DB 來、不從 header
return await rag.ask(body.query, auth.user_id, tenant_id)Takeaway:JWT + membership 是兩件事。JWT 證身份(你是誰)、membership 證授權(你能進哪)。Production ACL 一定要兩層都有。
第三條主線:查得到(document APIs + citation viewer)
第 6 站:document APIs——管理後台的接口
User 上傳文件、列出文件、刪除文件、更新 metadata,這些操作不該直接戳 DB。
# ✅ Document APIs
@app.get("/documents")
async def list_documents(auth: AuthContext = Depends(verify_jwt)):
"""列出 user 看得到的文件(ACL 自動套用)"""
@app.post("/documents/upload-url")
async def get_upload_url(req: UploadRequest, auth: AuthContext = Depends(verify_jwt)):
"""拿 signed upload URL(限時 + 限 path)"""
@app.delete("/documents/{doc_id}")
async def delete_document(doc_id: str, auth: AuthContext = Depends(verify_jwt)):
"""刪文件(Postgres soft delete → Vector DB 刪 chunks → Storage 刪檔)"""
@app.patch("/documents/{doc_id}/metadata")
async def update_metadata(doc_id: str, req: MetadataUpdate, auth: AuthContext = Depends(verify_jwt)):
"""改 metadata(permission_groups / source_path 等)"""Takeaway:document APIs 是 user 跟系統之間唯一的接口——所有 ACL 都在 API 層強制、所有 audit log 都在 API 層記錄。管理後台直接戳 DB = ACL 繞過、audit log 沒留。
Document APIs 還有一個容易漏掉的責任:不要只回傳文件列表,也要回傳文件可被查證的結構狀態。如果 Part 09 前面保留了 page / bbox / section path / OCR confidence,管理端 API 就要讓這些狀態可見。
{
"document_id": "doc_123",
"title": "Q3 supplier contract.pdf",
"ingestion_status": "done",
"modalities": ["text", "table", "image", "layout"],
"element_counts": {
"text": 84,
"table": 6,
"image": 3
},
"quality_flags": {
"low_ocr_confidence_pages": [7, 18],
"tables_without_headers": 1
}
}這個 contract 讓三種人都知道系統狀態:user 知道文件是否可查,admin 知道哪份文件要重跑 parsing,developer 知道答案錯時該先查 ingestion 還是 retrieval。
反例(必看):為了「快速管理」寫 admin script 直接戳 DB。
# ❌ 反例:admin 為了快速清掉測試資料
async def cleanup_test_documents():
await db.execute("DELETE FROM documents WHERE source_path = 'test'")
# 沒過 ACL、沒記 audit log、後面查不到誰刪的反例情境:早期有 admin 用 psql 直接砍測試文件,後來某 user 投訴「我的文件不見了」、查 audit log 完全沒紀錄、花了兩天才從 backup 撈回來。所有寫操作都走 API = 不只是 ACL、是 auditability。
Part 01 的 demo 後台就是用 document APIs 串的——使用者看到的「上傳 / 列出 / 刪除」按鈕,後面是同一套 API。
第 7 站:citation viewer——可解釋性的最後一哩
每個答案附 [1] [2] 引用、點下去看到原文 + chunk ID + retrieval score。Part 06 講 retrieval 強化(hybrid + rerank + parent expansion)、Part 07 講 citation check(faithfulness 跟 source 對得起來),這裡講 citation 怎麼送到 viewer。
Payload 怎麼從 retrieve 流到 viewer——每個 stage 對 citation payload 貢獻一個欄位:
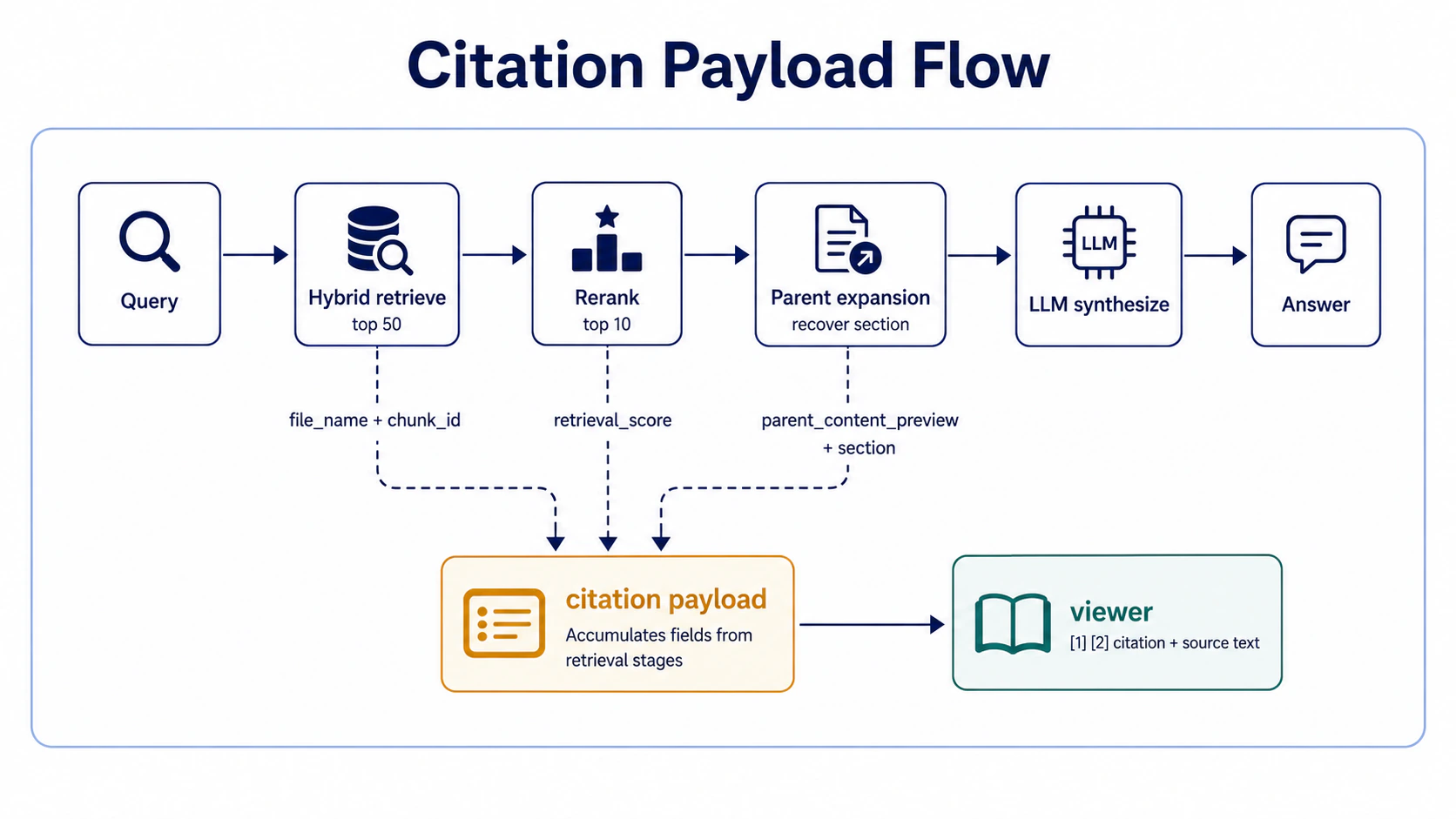
Payload 範例(不是 pseudo code、是實際送給 viewer 的 JSON shape):
{
"answer": "Q3 終止條款規定提前 60 天書面通知。",
"citations": [
{
"id": 1,
"file_name": "NatyNites-Q3-2024.pdf",
"chunk_id": "doc_abc_chunk_42",
"parent_doc_id": "doc_abc",
"section": "Article 5. Termination",
"retrieval_score": 0.92,
"parent_content_preview": "Article 5. Termination\nEither party may terminate this Agreement upon sixty (60) days prior written notice...",
"highlights": [
{"start": 0, "end": 87, "match": "Either party may terminate..."}
]
}
]
}Takeaway:citation 不只是「檔名 + 行號」——要有 chunk_id(debug 用)、retrieval_score(知道是 vector 撈到還是 keyword 撈到)、parent_content_preview(user 不用下載檔案就能 verify)、highlights(user 一眼看到哪段被引用)。
反例(必看):citation 只給「檔名 + 行號」。
// ❌ 反例
{
"answer": "Q3 終止條款規定提前 60 天書面通知。",
"citations": [
{"file_name": "NatyNites-Q3-2024.pdf", "line": 42}
]
}為什麼錯:user 看到「line 42」要自己去 PDF 翻第 42 行;debug 時不知道這個 chunk 是 vector recall 撈到(score 0.92)還是 keyword 撈到(score 0.4)、判斷不了 retrieval 哪個環節出問題;auditor 要 verify 答案真實性時沒原文、只能信 LLM。citation 設計不良 = 把可解釋性外包給 LLM 跟 user。
反例情境:早期 citation 只有檔名 + 行號,user 投訴「AI 亂講」時我們要回 PDF 找原文對、debug 一次 20 分鐘。後來 payload 加上 chunk_id 跟 retrieval_score,debug 變 30 秒——直接查 Qdrant payload 就知道哪個環節出問題。
Part 09 + Part 08 = production RAG 完整迴路
文件端(Part 09 7 站)跟 query 端(Part 08 5 mode)合起來才是 production RAG 的完整 closure:
文件進系統 → Part 09 站 1-5(parsing → storage → metadata → queue → ACL)
User 問問題 → Part 08 5 種 mode routing
→ Part 09 站 5 ACL 過濾 user 能看到的文件
→ Part 08 各 mode pipeline
→ Part 09 站 7 citation viewer
→ 答案 + [1] [2] 引用回到 user兩端各自獨立、缺一就破:文件端沒設計好(Part 09)→ cross-tenant leak、刪文件連 chunk 都找不回;query 端沒設計好(Part 08)→ 不管什麼 query 都跑同一套。兩端都做好,Part 01 互動 demo 跑的就是這條 closure。
Part 10 接著拆「把這套推上 production 的那 3 個月、11 個坑」——部署時這 7 站各自會出什麼問題、ACL 哪一層先破、citation viewer 怎麼監控、ingestion queue 怎麼 scale。