一個具體失敗案例
我這個專案早期有一個 query 一直答不對:
「這份 Q3 合約的 early termination 條款,違約金怎麼算?」
Vector search 找到了對的文件——mou_2025_003.pdf 在 top 3。但 LLM 答出來的是:early termination 走 30 天書面通知、違約金由雙方協商。
事實是合約寫得很清楚:early termination 要 60 天通知、違約金是 6 個月訂閱費。文件找到了,答案還是錯的。
為什麼?回去 trace 一輪發現:vector search 撈到的是這份 MOU 的「合作範圍」跟「付款條款」兩個 section——它們都在 top 5,但 LLM 沒撈到第三段那個明確寫 early termination 跟違約金的條款。為什麼沒撈到?因為「early termination 違約金」這幾個字的 dense embedding 跟「合作範圍」這段文字的 embedding 距離比較近,跟第三段的 dense embedding 反而遠一點。
換個角度講:dense vector 抓的是「語意相似」,不是「真的能回答問題」。向量距離近 ≠ 段落內容能答這個 query。Vector search 本身沒有「對錯」概念,它只算「像不像」——這個 gap 是 naive RAG 系統性失敗的根因。
這就是純 vector search 的極限:找到「相關」的文件,但不一定找到「對」的段落。
Tested API shape 提醒:本文程式片段示範的是這個專案採用的實作形狀,不是永久不變的 SDK contract。請 pin Python 套件版本,替每段關鍵 snippet 保留最小 smoke test,升級 LlamaIndex / Qdrant / FastAPI / eval framework 前先對照官方文件。
找得到跟答得好是兩件不同的事
Vector search 找的是「語意相近」,不是「真的能回答這個問題」。
naive RAG 把這兩件事當同一件事:撈到 top 5 → 餵給 LLM。但 production 場景下,這個假設幾乎一定會破——你要嘛找到「語意近但答不了」、要嘛「答案在但語意遠所以沒撈到」。
Retrieval layer 決定答案品質的上限,不是 LLM。 LLM 再強,如果檢索給的是錯的段落,它只能基於錯的段落生成答案。LLM 換成更好的 model 也沒救——檢索漏了,模型再強也補不回來。
這個專案把 70% 精力花在 retrieval layer(hybrid search、reranking、parent expansion、context compression、citation assembly),就是為了把「找得到」這件事做對。LLM 部分只佔 30%。
這個專案加的 4 個 retrieval 強化
純 vector search 不夠。4 個強化加上去後,剛才那個 early termination query 答對了。
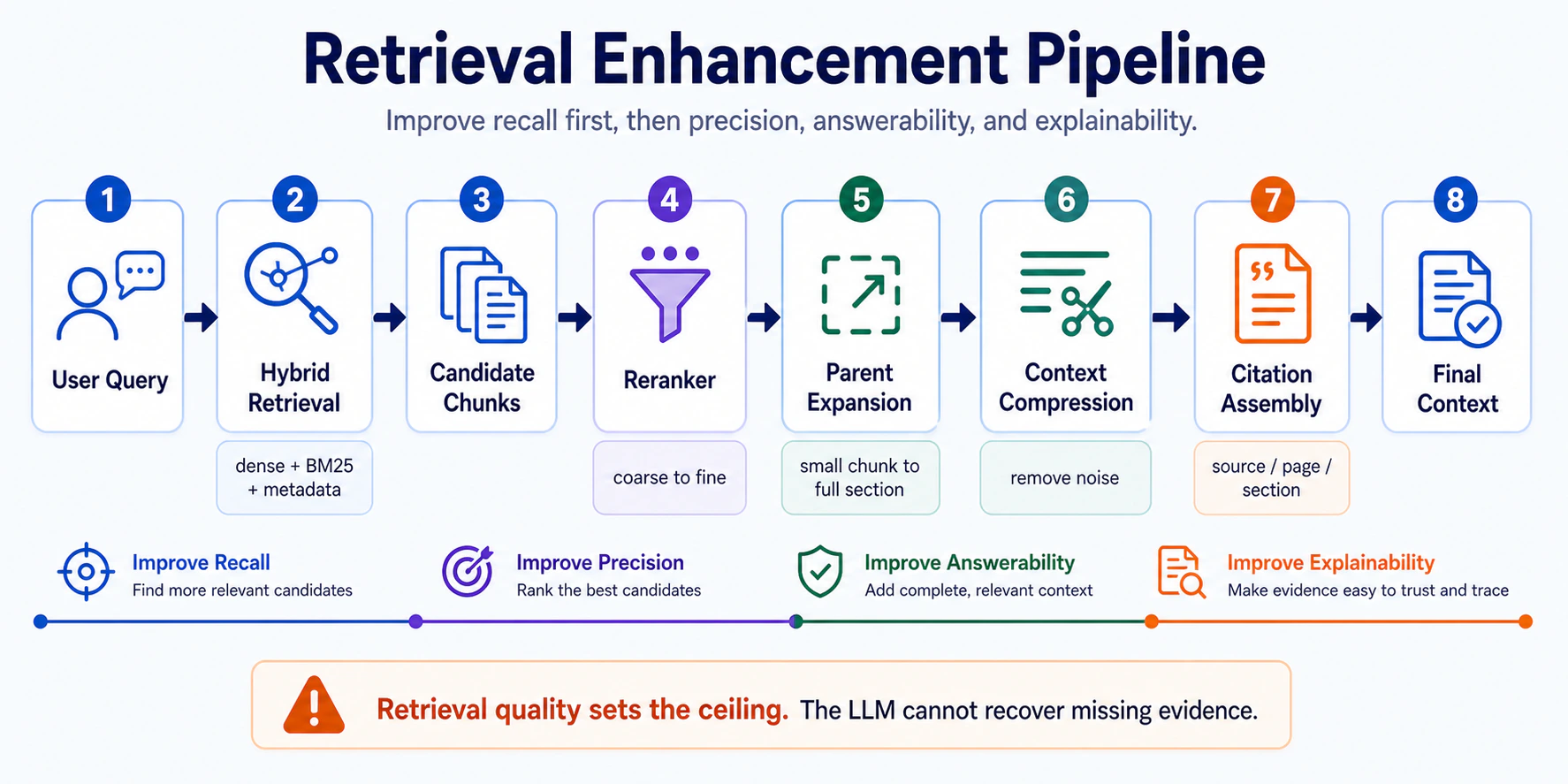
這條 pipeline 的順序很重要:先把 recall 拉起來,再用 reranker 拉 precision,接著用 parent expansion / compression 讓答案有足夠上下文,最後用 citation assembly 讓每個重要主張都能追回來源。這不是「多加幾個 feature」,而是把 retrieval 從「找相近」變成「找得到、排得準、答得完整、查得到根據」。
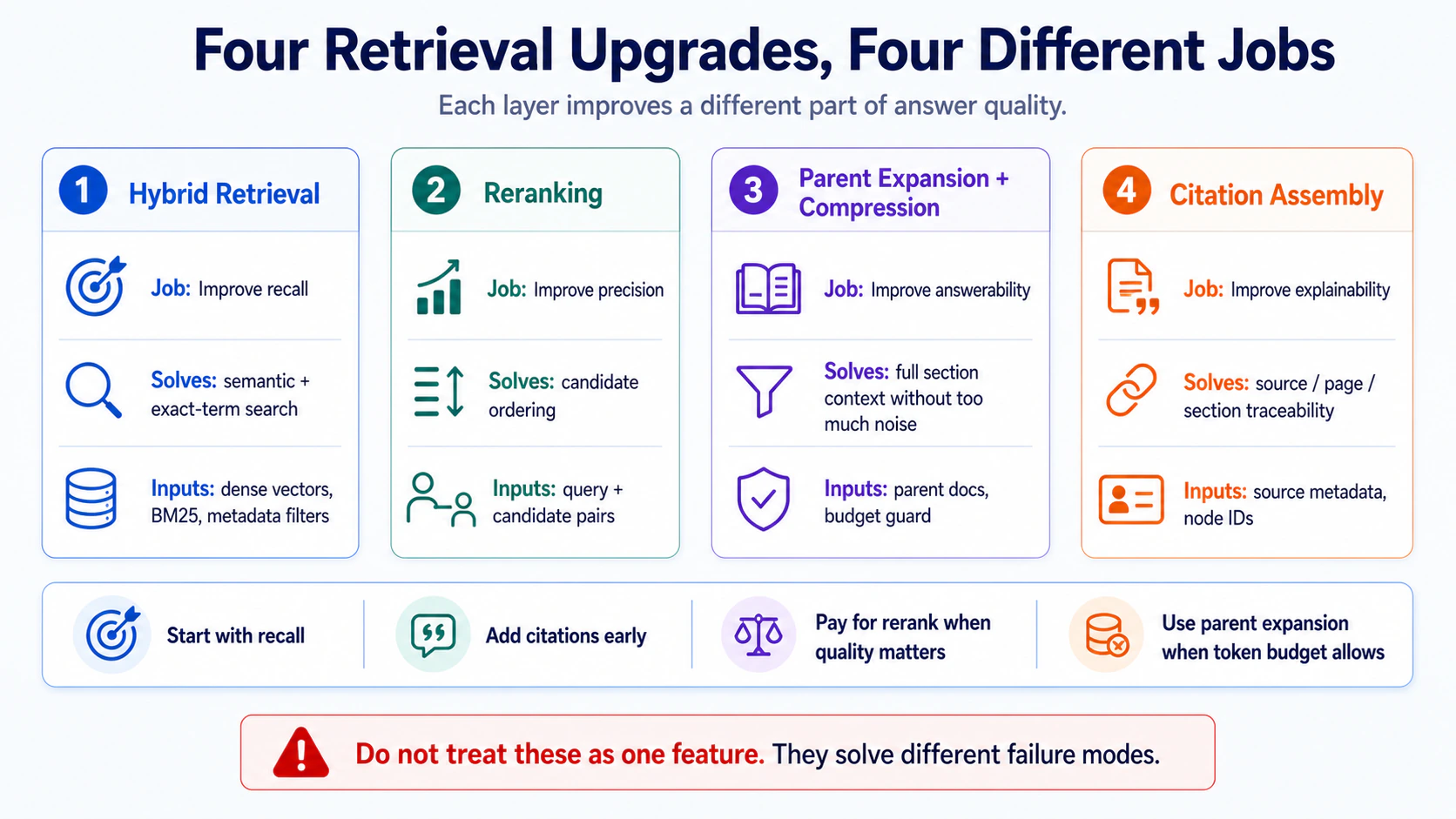
強化 1:Hybrid retrieval(dense + BM25 + metadata)
Dense vector 抓語意、BM25 抓精確字串、metadata filter 限制範圍。三個一起跑、再用 RRF(Reciprocal Rank Fusion)合併。
建 hybrid collection(Qdrant named vectors):
from qdrant_client import QdrantClient
from qdrant_client.http import models
def create_hybrid_collection(client: QdrantClient, name: str) -> None:
client.create_collection(
collection_name=name,
vectors_config={
"dense": models.VectorParams(size=384, distance=models.Distance.COSINE),
},
sparse_vectors_config={
"sparse": models.SparseVectorParams(index=models.SparseIndexParams()),
},
)查詢端用 LlamaIndex Qdrant integration:
from llama_index.vector_stores.qdrant import QdrantVectorStore
def get_hybrid_store(client: QdrantClient, name: str) -> QdrantVectorStore:
return QdrantVectorStore(
client=client,
collection_name=name,
enable_hybrid=True, # dense + sparse 同時建
fastembed_sparse_model="Qdrant/bm25",
hybrid_fusion_fn="rrf", # Reciprocal Rank Fusion 合併
# 加上 metadata filter:document_type、language、tenant_id
)為什麼 BM25 不能省? 同一個 query 換幾種問法:
| 問法 | Dense vector | BM25 |
|---|---|---|
| 「這份 Q3 合約的 early termination 怎麼算」 | 中(語意近) | 強(命中 early termination) |
GET /users/me/profile | 弱(純字串) | 強(完全命中) |
INV-2025-003 | 弱 | 強 |
| 「終止合約要走什麼流程」 | 強 | 弱(沒命中「終止」) |
Dense 強的地方 BM25 弱,BM25 強的地方 Dense 弱。production 不是二選一。早期 RAG 系統只跑 dense search,後來出事,9 成都是 dense search 沒撈到該撈的精確字串條款。
中文 + BM25 的獨特坑:很多 BM25 預設偏英文斷詞,中文要另外驗證。LlamaIndex 的 Qdrant hybrid integration 用 Qdrant/bm25 model 透過 FastEmbed 跑。下面第一段只驗證「FastEmbed 對中英混合 query 有產生非空 sparse vector」,它不能證明 Jieba 有被 Qdrant/bm25 使用。
from fastembed import SparseTextEmbedding
# Qdrant/FastEmbed sparse-vector sanity check。
# 這段只驗證 sparse output 存在,沒有設定 custom tokenizer。
sparse_model = SparseTextEmbedding(model_name="Qdrant/bm25")
query = "early termination 違約金"
sparse_vec = list(sparse_model.embed([query]))[0]
non_zero = len(sparse_vec.values)
assert non_zero > 0, f"Qdrant/bm25 產生空 sparse vector: {non_zero}"如果你要測的是「中文斷詞本身」,要用 tokenizer 真的有被傳進 index 的 local BM25 檢查:
import jieba
from rank_bm25 import BM25Okapi
def chinese_tokenize(text: str) -> list[str]:
return [t for t in jieba.cut(text) if t.strip()]
documents = [
"提前終止需要 60 天書面通知,違約金為 6 個月訂閱費。",
"付款條款為每月結算,發票到期日為 30 天。",
"合作範圍包含資料串接與系統維運。",
]
tokenized_docs = [chinese_tokenize(doc) for doc in documents]
bm25 = BM25Okapi(tokenized_docs)
query_tokens = chinese_tokenize("提前終止 違約金")
scores = bm25.get_scores(query_tokens)
assert scores.argmax() == 0別看到「hybrid」就以為中文也吃。要分開驗證兩件事:第一,Qdrant/FastEmbed sparse vector 是否有正常輸出;第二,你實際採用的中文斷詞策略是否真的進到 BM25 index 裡。
強化 2:Reranking(粗找 → 精排)
Hybrid search 撈 50–200 個候選,reranker 用 cross-encoder 重新排序,把真正有用的 5–20 個排到前面。
完整 query engine pipeline(含 hybrid + rerank + LongContextReorder + 壓縮):
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.postprocessor import LongContextReorder
from llama_index.postprocessor.cohere_rerank import CohereRerank
from llama_index.core.response_synthesizers import CompactAndRefine
postprocessors = [
LongContextReorder(), # 重要 chunk 放頭尾(LLM 注意力集中在頭尾)
CohereRerank(top_n=8, model="rerank-english-v3.0"),
]
query_engine = RetrieverQueryEngine.from_args(
retriever=retriever,
node_postprocessors=postprocessors,
response_synthesizer=CompactAndRefine(),
)為什麼 hybrid 之後還要 rerank? Hybrid 合併 RRF 是粗排——把多個排序融合成一個,但 rerank 用 cross-encoder 對(query, candidate)做語意比對,比純向量比對精準很多。以這個專案的量測來看,Hybrid + Rerank 一起做,跟單獨做差距約 20-30%。
主流選項:Cohere Rerank(managed,馬上能跑)、BGE reranker(自架,成本可控)、Jina / Voyage(多語或重檢索場景)。Qdrant 有 ColBERT / multivector 內建選項但比較進階,新手先用外部 reranker。
強化 3:Parent-doc expansion + Context compression
小 chunk 好搜尋、大 parent 好回答。先用小 chunk 找位置,再把所屬大段落拿回來。
from llama_index.core.schema import TextNode
async def expand_to_parent(node: TextNode, docstore) -> TextNode:
"""把搜尋到的小 chunk 換成它的 parent section"""
parent_id = node.metadata.get("parent_id")
if not parent_id:
return node
parent = await docstore.aget(parent_id)
return parent or nodeCompression 把不相關的句子過濾掉,只留跟 query 有關的內容。好處:省 token、降低雜訊、減少 LLM 亂引用的機率——特別是 chunking 切得比較大的時候,compression 效果最明顯。
補一個 pattern:Long-context Hybrid
Long-context Hybrid 不是「把所有文件都塞進 context window」。那只是把 retrieval 問題改名成 token 問題。
比較準確的定義是:先 retrieval,再對少數高相關 parent docs 做 smarter packing。 它通常長在 parent expansion 和 context compression 之間:先用 hybrid + rerank 找到候選,再把最有可能回答問題的 parent section / document 拉回來,最後用 compression、ordering、budget guard 決定哪些內容真的進 prompt。
什麼時候適合一般 top-k retrieval?
- 問題只需要一兩段明確 evidence
- 答案集中在單一 section
- 使用者要的是精準引用,不是整體歸納
- latency / token budget 很緊
什麼時候適合 Long-context Hybrid?
- top-k chunk 很碎,單段 evidence 不足以回答
- 問題需要跨同一份文件的多個 section
- 文件本身有強烈順序,例如合約、政策、規格書、研究報告
- 你需要保留前後文,避免 LLM 斷章取義
一個簡單決策規則是:如果 rerank 後 top chunks 來自同一份文件、相鄰 section,而且每段分數都不低,就不要只丟 top-k;改拉 parent document,再做 compression。 這樣比「全文件塞入」便宜,也比「碎片 top-k」穩。
強化 4:Citation assembly(自訂 citation mapper)
把每個答案綁回 source。這不只是顯示「來源 [1]」給使用者看——是讓你能驗證 LLM 到底憑什麼答。
from pydantic import BaseModel, Field
from typing import Optional
class CitationItem(BaseModel):
marker: str = Field(..., description="Inline marker like [1]")
file_name: str
page_number: Optional[int] = None
section_title: Optional[str] = None
node_id: str
text_preview: str
retrieval_score: float = 0.0
def map_citations(response) -> list[CitationItem]:
"""把 response.source_nodes 轉成前端可用的引用清單"""
return [
CitationItem(
marker=f"[{i+1}]",
file_name=node.metadata.get("file_name", "unknown"),
page_number=node.metadata.get("page_number"),
section_title=node.metadata.get("section_title"),
node_id=node.node_id,
text_preview=node.get_content()[:200],
retrieval_score=float(node.score or 0),
)
for i, node in enumerate(response.source_nodes)
]為什麼不直接用 LlamaIndex 內建的 CitationQueryEngine? 這個專案的 context 經過「Qdrant → reranker → parent expansion → compression → LongContextReorder → custom prompt」這幾層處理,真正送進 LLM 的 source 跟 response.source_nodes 對不上。內建 citation 引擎的 marker regex 在 long-context reorder 跟 marker 替換之後會壞掉——這個反例是實際踩過的坑,不是理論風險。自訂 citation mapper 才是 production 級做法。
這些強化的 tradeoff(具體數字)
不是加了越多越好。每一層強化都有成本——下面數字會標出性質:專案實測代表這個實作裡觀察到的結果,起步 heuristic代表上線前可先採用但必須用自己的 workload 驗證的預設值,外部價格 / benchmark代表供應商價格或常見業界基準,不是官方保證值。
| 強化 | 品質影響 | 成本影響 | 可解釋性影響 |
|---|---|---|---|
| Hybrid retrieval | 專案實測:retrieval recall +20-30% | 起步 heuristic:Storage 約 2x(dense + sparse vectors);專案實測:查詢 latency +50-100ms;中文需額外斷詞驗證 | 中(合併規則 RRF 簡單) |
| Reranking | 專案實測:top-k 排序正確率 +25-35% | 外部價格 / benchmark:Cohere Rerank $0.001-0.005/query(per 1000 tokens);自架 BGE reranker 加 GPU 成本;專案實測:latency +200-500ms | 低(cross-encoder 黑盒) |
| Parent expansion | 專案實測:答案完整度 ↑;LLM 亂引用率 ↓ | 起步 heuristic:Token 花費 5-10x(每個 chunk 從 100 字變 1000 字);專案實測:latency +100-300ms | 高(能追到 section) |
| Long-context Hybrid | 跨 section answerability ↑;斷章取義 ↓ | Token 花費介於 top-k 與 full-doc stuffing 之間;需要 budget guard / ordering | 高(保留 parent doc 與 section path) |
| Context compression | 專案實測:雜訊 ↓;亂引用 ↓ | 外部價格 / benchmark:略增 reranker 呼叫($0.0001/query);專案實測:latency +50-150ms | 中(要看 compressor 邏輯) |
| Citation assembly | 專案實測:可驗證答案來源 | 專案實測:低成本(純 mapping);latency +10-50ms | 最高(直接綁回 source) |
預算有限的取捨:先做 hybrid retrieval(找得到是基本盤)→ 再做 citation assembly(成本最低、可解釋性最高)→ 然後再做 reranking(品質提升明顯但有成本)→ 最後做 parent expansion / Long-context Hybrid(看 token 預算與問題型態)。
另一個關鍵觀察:LLM 換成更強的 model 對答案品質的邊際效益越來越低,但 retrieval 強化每加一層都還有明顯邊際效益。當 LLM 已經是 GPT-4 等級,再花錢升級 model 帶來的答案品質提升 < 加一層 reranking 帶來的提升——預算有限時,錢花在 retrieval 比花在 LLM 划算。
這也解釋了為什麼這個專案從 V0 到 V3 都用同一個 LLM 設定,換了 4 次 retrieval 強化——retrieval 才是拉開差距的主戰場,LLM 換強一點的邊際效益太低。
Part 01 的互動 demo 跑的就是這個專案的 production pipeline——你可以直接拿那個 early termination 查詢去問、看 trace 怎麼流。Part 07 拆「production 跟 demo 的差距」——faithfulness check、citation check、offline eval、Langfuse tracing、cost tracking,這 4 層 retrieval 強化加上去後,怎麼量化它們實際拉高多少答案品質,是 Part 07 的核心問題。rag/retrieval.py、rag/compression.py、rag/citations.py 這幾個模組就是 Part 06 這 4 層強化的具體落實。