故事:寫完最後一行的那天
從第一行程式碼,到 production HTTPS endpoint,到最後一份「Production Checklist」蓋上——整個專案跑完一輪。
那天我打開 dev notes 從頭翻。看起來像完成品,但越看越像座標系。
每個改動是一個能力點。但「能跑」跟「能讀懂別人為什麼這樣設計」是兩件事。一個完成品是「這些能力有沒有」;一座標系是「這些能力怎麼互相牽動、哪個是底層、哪個是上層、哪個可以拆、哪個不能拆」。
這篇 Part 11 不是前 10 篇的目錄摘要,是把整個專案重新編碼成 3 個層級最高的觀察。具體的技術細節 Part 02-10 各自講過;這篇談的是做完才看懂的東西。
這 3 件事是:
- 能力可以收:11 個 flag 收成 5 種 mode,是從「功能導向」到「系統導向」的轉折
- 學習路徑可以重排:跑完一輪再回頭重排整個學習順序,是教學者必經的一次重構
- 什麼不做比做什麼更重要:被擱置跟明確不做的清單,比做掉的清單更值得講
但這篇還要多做一件事:把 Part 12 原本想談的 landscape 收回 Part 11。因為系列收束不只需要回顧「我做了什麼」,也要誠實標出「這套 production core RAG backbone 在 2026 的 RAG 地圖裡站在哪裡」。
寫在前面:這 3 件事不是「我的成功經驗」,是「做完才看出來的結構」。如果你現在正在做一個 RAG 專案,希望這 3 件事能幫你少走一段。
Landscape 版本提醒:本文描述的是 2026 RAG landscape 的座標系,不是永久分類法。工具名與 API 會變;比較穩的是 retrieval、routing、context assembly、evaluation、observability、operations 之間的能力邊界。
觀點 1:11 個 flag 收成 5 種 mode
一開始的設計是 11 個獨立 flag:
auto_route
auto_rewrite
retrieval_mode
use_reranker
use_parent_expansion
use_context_compression
use_long_context_reorder
use_faithfulness_check
use_ragas_check
use_citation_check
use_llm_citation_judge每個 flag 開 / 關是一種行為,排列組合是幾十種 query pipeline。聽起來很彈性,實際上是在把決策外包給 caller。
問題很快就冒出來:
- caller 不知道哪個 flag 該開哪個該關
- 不同 caller 開了不同 flag,debug 時不知道這次 query 跑的是哪一條 pipeline
- 新增 capability 變成「再多加一個 flag」,整個系統越來越難讀
最後我把它收成 5 種 mode:
fast — 直接查,不評估
safe — 加 faithfulness check、citation
deep_eval — 同步跑 RAGAS、citation judge
creative — LLM-first synthesis
agentic — 允許 multi-step workflow、tool routing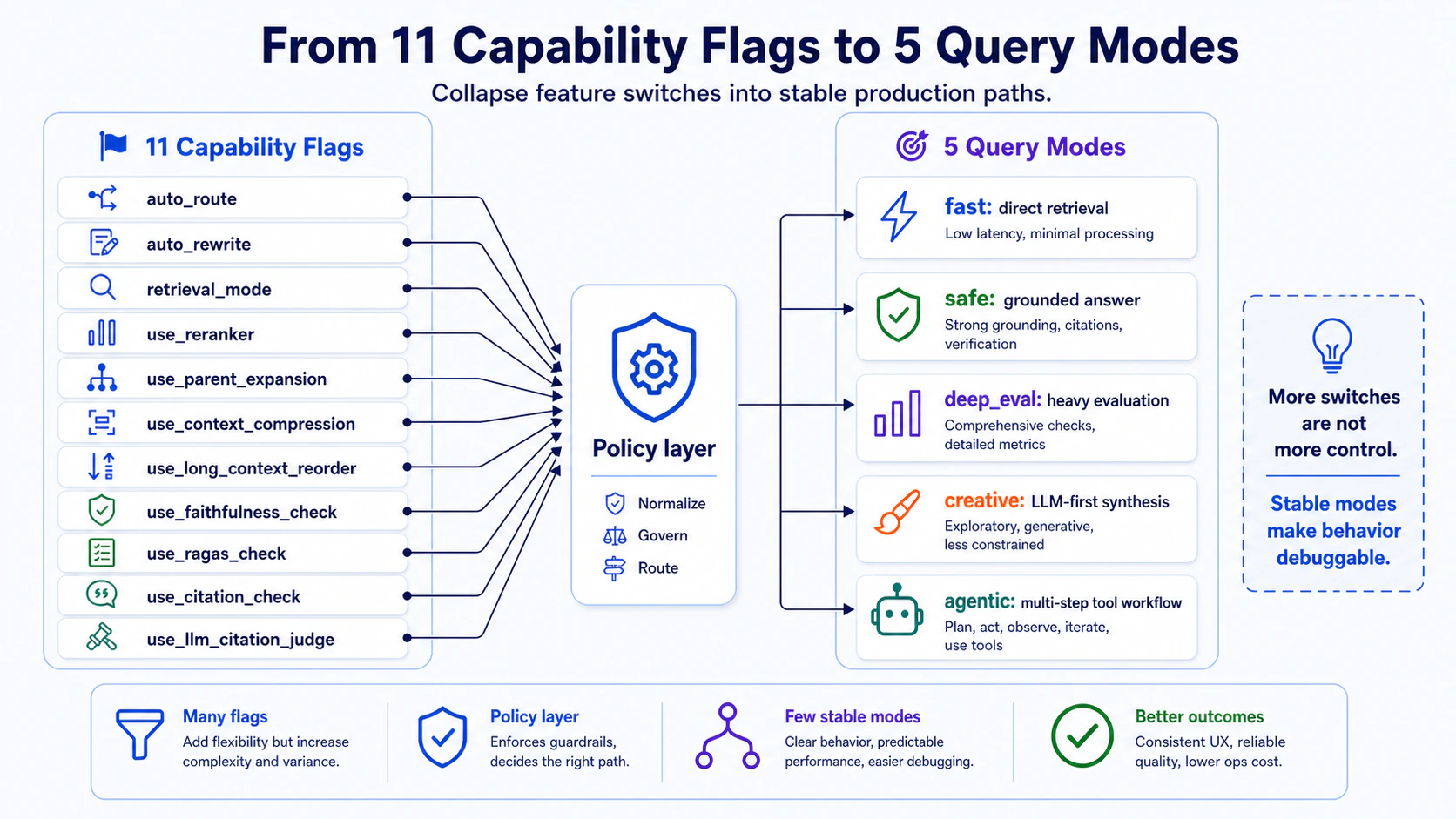
收完之後的差別:
- caller 只要選 mode,不用想 flag 組合
- pipeline 是確定的幾條(5 條),debug 時直接看 mode 知道跑了哪條
- 新增 capability 的決策變成「這個能力歸到哪個 mode」而不是「再多加一個 flag」
Takeaway:當你的系統有超過 5 個獨立 binary switches,使用者實際上已經放棄理解整個系統。 收成 mode 是把「組合爆炸」變回「少數路徑」。
這件事是整個系列裡我做完才真正看懂的:不是每個 capability 都應該是使用者選的開關。 把它收成幾種 mode 是系統設計,不是介面美觀。
觀點 2:跑完一輪,再回頭重排學習路徑
這個專案我邊做邊寫教學筆記。原本的學習路徑是按「我會什麼、所以先教什麼」排的:
- LlamaIndex Workflows
- Tool Routing
- MCP Tool Call Integration
- Evaluate / Reflect / Refine / Retry Loop
- FastAPI Auth
- Dockerize FastAPI + Qdrant
- Deploy to VPS
- Cloud Deployment Options跑完一輪實作之後,我發現這個順序有兩個問題:
- Tool routing 跟 MCP 放在 Workflows 之後:但 Workflows 內部會用到 tool routing;先教 Workflows 再教 tool routing 會讓學生卡在「Workflows 怎麼 dispatch tool」
- FastAPI Auth 跟 Docker 分開:但實際上 Auth 的 middleware 跟 Docker 的 port 規劃是耦合的,分開教會讓學生在 deploy 階段才發現「auth 在 container 內部不能用 loopback」
所以我把整個路徑打散重排。重排後的順序是按「學生真實的卡點」排的,不是按「我會什麼」排的:
- Production Query Modes / Cost Profiles
- Runtime Budget Guard
- LlamaIndex Workflows
- Tool Routing
- MCP Tool Call Integration
- Reflect / Refine / Retry Loop
- Async Evaluators
- Ingestion Job Queue
- FastAPI Auth + Permission-aware Retrieval Hardening
- Document Management APIs
- Citation Source Viewer Payload
- Dockerize FastAPI + Qdrant + Worker
- Cloud Deployment Options
- Oracle E2 + Qdrant Cloud decision
- Deploy API to Oracle E2 + Qdrant Cloud
- Cloudflare domain + HTTPS
- Production Checklist Final PassFastAPI Auth 從原本的第 5 個移到「Docker 化之前」——因為 auth 在 container 內不能用 loopback,這是部署時才會撞到的耦合。
這件事 Part 03、Part 04 沒講,Part 11 才講——因為這不是教學內容,是教學設計本身。
Takeaway:做完一輪實作再回頭重排學習路徑,是教學者必經的一次重構。第一次排路徑是用「我會什麼」排的;重排是用「學生卡在哪」排的。後者比前者重要。
觀點 3:什麼不做,比做什麼更重要
Part 02-10 走的是「做出來」。但一個 production RAG 真正能穩定跑,不只是因為做了什麼,是因為明確選擇不做什麼。
這裡只列被擱置的項目(不在本系列做的範圍內):
- 多 LLM provider 抽象層(Anthropic / OpenAI / Gemini 同時支援)
- Self-hosted Qdrant(目前用 Qdrant Cloud)
- Streaming response(目前是完整 answer 回傳)
- WebSocket 推播(citation 變化主動通知 client)
- Multi-region failover(VM 只在 us-ashburn-1)
- Production-style observability stack(Prometheus + Grafana + alert)
- A/B testing framework(5 種 query mode 沒做流量切分)
- Fine-tuning embedding model(用現成的 OpenAI / BGE)
- RAGAS / LLM judge 改用本地模型(目前用雲端 LLM)
- 自家 prompt registry(prompt 散落在各 module 內)每一條都「可以做」。每一條都「目前不做」。
為什麼這比 Done 重要:
被擱置的存在代表你知道自己沒有在做什麼。一個 RAG 專案的「沒做」清單比「做過」清單更能告訴你這個系統的成熟度。
- 「我們 production 跑了」→ 什麼意思?流量多大?SLA 多少?沒說
- 「我們有 10 個 capability flag」→ 然後呢?caller 怎麼用?沒說
- 「我們沒做多 LLM 抽象」→ 為什麼?成本?時間?vendor lock-in?這個理由才是真訊息
系列設計筆記:這份清單整理自專案一路累積下來的 deferred scope 與結尾假設,這裡把它改寫成明確的產品與架構邊界。
Takeaway:一個 RAG 專案的「沒做」清單是它的設計哲學。 把這份清單寫出來比把「做過」清單寫出來更難,也更有價值。
Enterprise-Grade Scope Matrix
因為系列名稱用了「企業級」,範圍就必須講清楚。這個系列裡的 enterprise-grade,不是宣稱「所有企業級 hardening 都已完成」。它指的是 RAG backbone 已經不再停留在 demo:retrieval 有權限意識、答案可 grounded / citation、query mode 依風險分流、evaluation 與 trace 存在、deployment 約束也被攤開。
下面這張表就是邊界:
| 面向 | 本系列已覆蓋 | 有定位但未完整實作 | 本系列範圍外 |
|---|---|---|---|
| Retrieval / context quality | hybrid retrieval、reranking、parent expansion、context compression、citation assembly | Long-context Hybrid 作為 routed pattern | domain-tuned embedding / reranker training |
| Auth / tenant isolation | JWT + membership check、tenant filter、Postgres RLS pattern、cross-tenant test checklist | 完整 enterprise IAM / SSO / SCIM mapping | 組織級 identity governance |
| Evaluation / answer governance | faithfulness check、citation check、RAGAS offline eval pattern、model/eval governance 作為專案 discipline | multi-judge eval、人工抽樣審查、prompt registry | 受監管產業的 model-risk management program |
| Observability | Langfuse-style tracing、stage-level trace、latency / cost visibility | production alerting、Prometheus / Grafana、OpenTelemetry rollout | 完整 NOC / on-call platform |
| SLO / SLA / load testing | query mode 層級的 latency / cost budget;用 p95 當工程訊號 | 正式 SLO/SLA 目標、load test plan、traffic capacity model | 對客戶承諾的 contractual SLA |
| Data protection | metadata / ACL 設計、permission-aware retrieval、storage separation | PII classification、audit logs、retention policy、DLP review | 完整 privacy compliance program |
| Secrets / cryptography | environment hygiene、HTTPS / Cloudflare Origin Certificate、private-key handling | KMS、secret rotation、certificate rotation calendar | 企業級 key-management policy |
| Reliability / recovery | Docker deployment、health checks、index-not-ready graceful behavior | backup restore drill、incident runbook、DR plan、multi-region failover | 已驗證 RTO/RPO 的 HA platform |
| Supply chain / release | Git、Docker、deployment smoke tests | SBOM、dependency scanning、signed artifacts、release gates | 完整 secure SDLC certification |
| Prompt / agent security | bounded query modes、tool timeout、budget guards、final verifier | prompt injection test set、tool allowlist policy、abuse monitoring | 全 agent surface 的 red-team program |
所以比較誠實的 scope statement 是:
本系列覆蓋的是 production RAG backbone,以及讓它可檢查、權限感知、可引用、可評估、可部署的工程控制。它會定位周邊 enterprise hardening 工作,但不宣稱已完成大型企業平台所有 SRE、安全、合規、隱私與治理要求。
對齊 Part 10:這是我的選擇,不是通用建議
Part 10 結尾講了 4 個架構選型(Oracle VM / Qdrant Cloud / Cloudflare / Docker Compose)。那 4 條是「系統層」的選型。Part 11 這篇做的 3 個選型是「方法論層」的。
| 選型 | Part 10(系統層) | Part 11(方法論層) |
|---|---|---|
| VM 怎麼選 | Oracle Cloud Always Free | — |
| Vector DB 怎麼選 | Qdrant Cloud | — |
| HTTPS 怎麼選 | Cloudflare Origin Cert | — |
| 編排怎麼選 | Docker Compose(不選 k8s) | — |
| Capability 怎麼管 | — | 11 flag → 5 mode |
| 學習路徑怎麼排 | — | 用 production 順序重排 |
| 範圍怎麼定 | — | 明確被擱置的清單 |
同樣的原則:這 3 條是「我為什麼這樣選」,不是「你應該這樣做」。如果你正在做不同的 RAG 專案,結論可能完全相反——例如你的 caller 是工程師團隊、11 個 flag 也許 OK;你的課表是給 expert 看的、production 順序不一定是對的;你的「沒做」也許根本不需要被擱置。
這 3 條的共同點不是「我的答案是對的」,是「我做完之後真的知道自己選了什麼、也知道自己放棄了什麼」。這才是 closure。
2026 Production RAG Landscape:這個系列站在哪裡
如果只看 Part 02-10,這個系列像是一條完整的 production RAG 實作路線:從 chunk / embedding / retrieval,到 query router、ingestion、ACL、deployment。這條路線很重要,但它不是 2026 production RAG 的全部。
更準確的說法是:這個系列完成的是 Production Core RAG Backbone。
這個 backbone 包含六層:
| 層級 | 這個系列裡對應的位置 | 解的問題 |
|---|---|---|
| Ingestion | Part 03、Part 09 | 文件怎麼進來、怎麼保存、怎麼帶 metadata / ACL |
| Retrieval | Part 02、Part 06 | 怎麼從 dense-only 走到 hybrid / rerank / parent expansion |
| Context Assembly | Part 03、Part 06 | 怎麼把候選內容組成 LLM 能可靠使用的 context |
| Verification | Part 07、Part 08 | 怎麼檢查 groundedness、citation、final answer |
| Observability | Part 07、Part 10 | 怎麼 trace、debug、量測成本與延遲 |
| Deployment | Part 10 | 怎麼讓 API、DB、vector store、HTTPS、worker 真的活在 production |
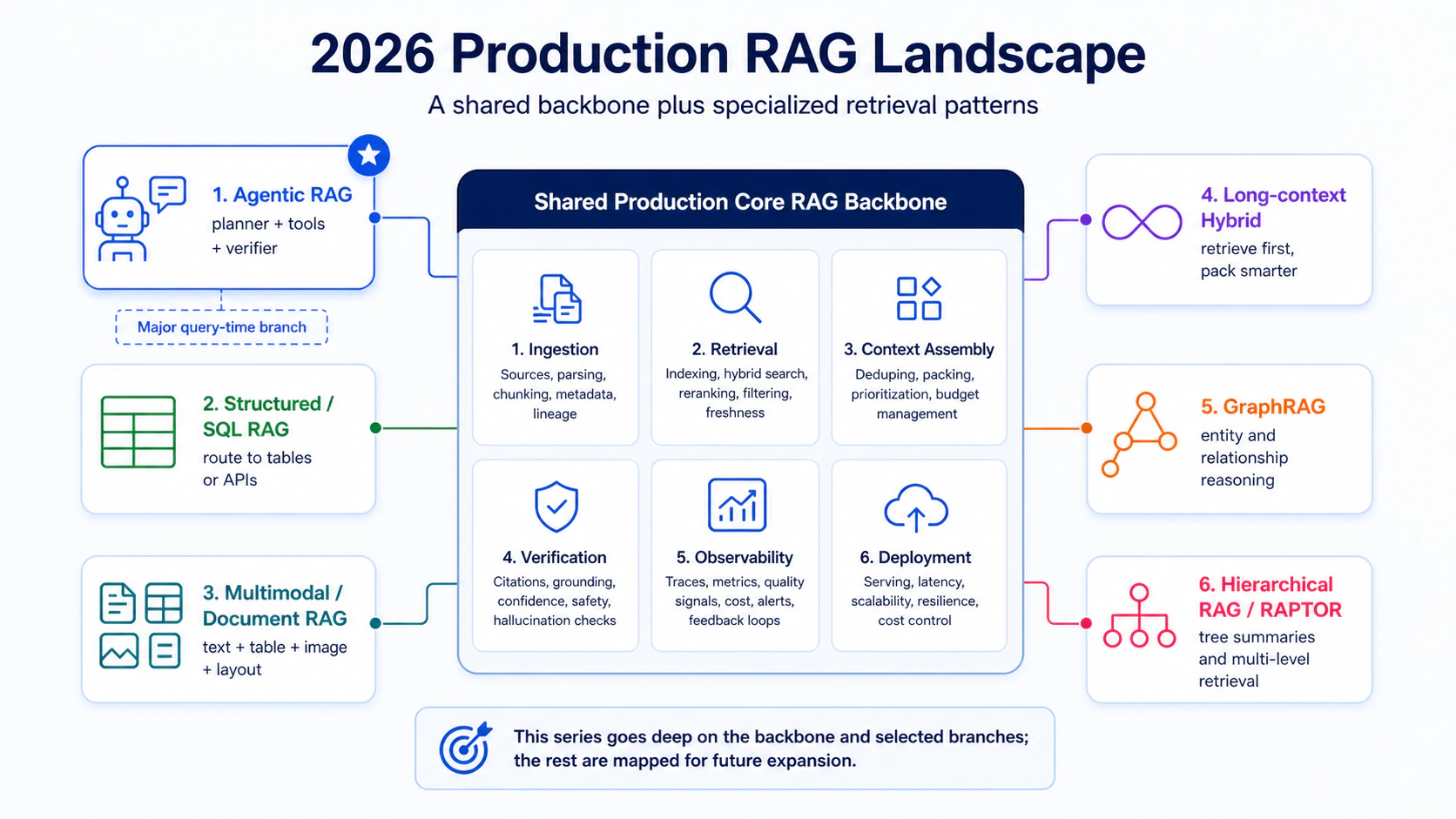
在 backbone 之外,2026 的 production RAG 還有幾個 specialized patterns。它們不是互相取代,而是長在同一條 backbone 上,解不同類型的問題。
| Pattern | 在這個系列的位置 | 這次深入程度 | 什麼時候需要 |
|---|---|---|---|
| Agentic RAG | Part 08 主舞台,Part 07 / 11 補觀測與 landscape | 深入 | query 需要 planning、tool routing、retry、final verifier |
| Structured / SQL RAG | Part 08 主放,Part 03 補入口 | 中等 | 問題答案在 table、DB、API,而不是文件段落 |
| Multimodal / Document RAG | Part 09 主放,Part 03 補入口 | 中等 | 文件裡有表格、圖片、版面、OCR、bbox citation |
| Long-context Hybrid | Part 06 主放,Part 08 補 routing decision | 中等 | top-k 太碎,但全文件塞進 context 又太貴 |
| GraphRAG | Part 11 landscape 定位 | 只定位 | 答案依賴 entity / relationship / community structure |
| Hierarchical RAG / RAPTOR | Part 11 landscape 定位 | 只定位 | 長文件或大型語料需要 tree summaries / multi-level retrieval |
這個表的重點不是「本系列沒有講完所有東西」。相反,它是在做 closure 時最該講清楚的事:我深入的是哪一層,我只是標出位置的是哪一層。
如果你正在規劃自己的 RAG 系統,我會建議先問這個問題:
我現在缺的是 backbone,還是 specialized pattern?
很多團隊其實還沒有穩定的 ingestion、metadata、citation、trace,就急著上 GraphRAG 或 agent。這通常不是升級,而是把尚未穩定的問題搬到更複雜的層上。反過來,如果你的 backbone 已經穩了,specialized pattern 就是下一個真正拉開上限的地方。
這也是為什麼這個系列的主線不是「追最新名詞」,而是先把 backbone 講完整,再把 specialized patterns 放回正確位置。
整個系列的 closure 長什麼樣
Part 01 是互動 demo 入口。Part 02-10 走一整段。Part 11 把它們收成座標系。
但「座標系」是什麼意思?不是「這套能力有 X、Y、Z」——是「這套能力怎麼互相牽動、讀的人可以怎麼進來」。
我自己的進來方式是:
- 想理解 RAG 怎麼跑 → Part 02、03
- 想看真實專案長什麼樣 → Part 05-09
- 想把 RAG 推上 production → Part 10
- 想看整個專案怎麼讀、怎麼評估自己的進度 → Part 11(這篇)
- 想做選型比較 → Part 04(回頭看)
讀者從哪裡進來都行。Part 11 不是「最後一篇」,是「座標系的第一頁」——你讀完 Part 02-10 之後如果想看全景,回來看這篇;讀這篇之後如果對某段有興趣,跳回去看 Part 02-10。
給正在做 RAG 專案的讀者
這 3 件事如果要我對正在做 RAG 專案的讀者講,我會這樣講:
第一件事(flag → mode)是給系統設計者的提醒:當你覺得 flag 越加越多、caller 開始亂開關,停下來收成 mode。這不是介面簡化,這是系統設計。
第二件事(重排學習路徑)是給教學者的提醒:第一次排路徑是用「我會什麼」排的——重排是用「學生卡在哪」排的。如果你有教別人或記錄自己學習路徑的習慣,跑完一輪再回來重排。
第三件事(「沒做」清單)是給專案 owner 的提醒:「做過」清單是「我們做過了」;「沒做」清單是「我們沒做、也知道為什麼沒做」。後者比前者難寫、也更能幫你定位自己的進度。
如果這 3 件事裡面有任何一件讓你想停下來想一下,那就是 closure 的價值。